Vehla
Streamlining workflows on Mac devices is a daunting task, especially when users have to juggle multiple utilities to acc...
Best LLMs Startups & Tools
Recently Listed
31 launches
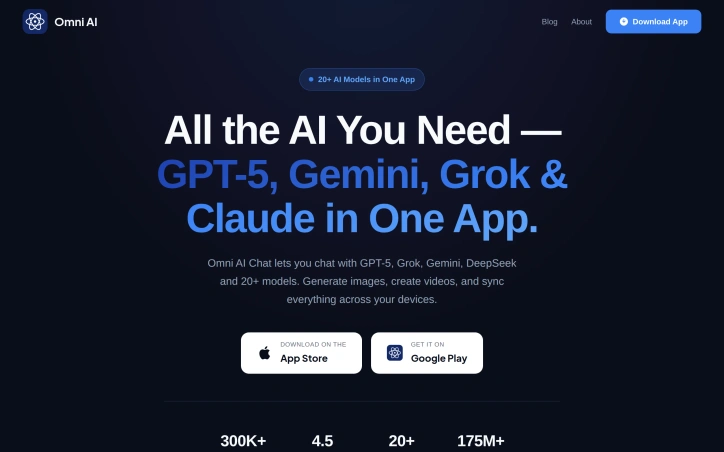
Teams that rely on AI models face a consistent risk: the quality of outputs depends directly on prompt quality. Poor prompts introduce hallucinations, leave systems vulnerable to injection attacks, and can inadvertently expose sensitive information. AIQualityHQ tackles this problem by providing instant validation for AI prompts before they reach production. The product is designed for developers and technical teams building AI-powered applications who need to ensure prompt safety and consistency without additional API costs or complexity. Its primary appeal is speed and transparency—the analysis engine runs locally in the browser within milliseconds, using deterministic structural rules rather than calling out to additional AI services. What distinguishes this product is its emphasis on deterministic analysis. Rather than relying on machine learning models or external APIs, AIQualityHQ uses rule-based heuristics and syntax checking to evaluate prompts across six dimensions: structure, memory, context, trust, privacy, and security. This approach means faster analysis (under 10 milliseconds), no privacy concerns from uploading prompts elsewhere, and results that do not depend on third-party API availability. The core workflow is straightforward: paste a prompt, run analysis, and receive both a quality score and specific recommendations for improvement. The platform flags common failure modes—prompt injection vectors, missing output constraints, exposed PII variables, and absent system instruction locks. For each issue detected, the tool provides actionable optimization suggestions rather than just reporting problems. Key capabilities include a diff view for comparing before-and-after versions of prompts and the ability to export results. The platform requires no signup and charges no fees, making experimentation low-friction. The product ships with example prompts to help users understand the analysis format. The main limitation appears to be scope: the tool focuses specifically on prompt quality rather than broader concerns like model selection, fine-tuning, or inference optimization. Users seeking comprehensive AI system auditing would need additional tools. Additionally, while browser-based analysis ensures privacy, it also means analysis is confined to what static rules can detect—issues that emerge only at runtime or in specific model behaviors may not surface. For teams managing multiple AI prompts in production or developing new AI features, this fills a genuine gap. The combination of zero cost, instant results, and focus on preventable failures makes it a practical addition to an AI development workflow.
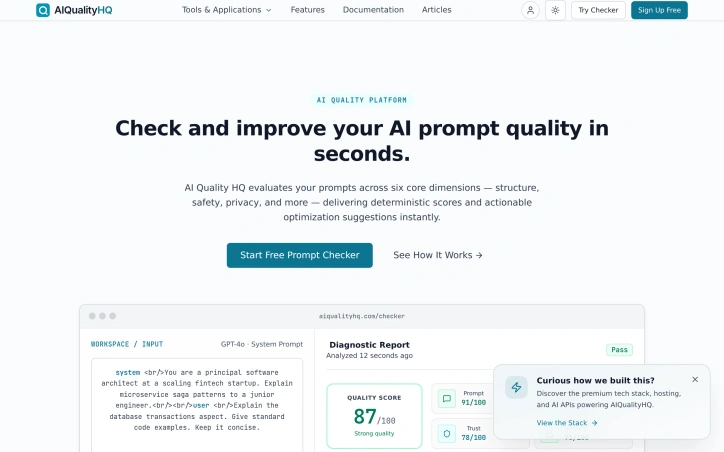

Repetitive customer service tasks drain time and resources from small businesses, yet affordable solutions that don't require engineering expertise remain scarce. ChatME addresses this gap by delivering an AI assistant that deploys in minutes without coding, training itself on your website content to handle bookings, customer inquiries, and order lookups around the clock. The product's core appeal lies in its simplicity and speed. Setup requires just three steps: paste your website URL, customize the bot's tone and appearance, then embed a single line of code. ChatME crawls your site to understand your business voice and operations, then goes live on your website and WhatsApp within the timeframe the company promises—10 minutes. This frictionless onboarding contrasts sharply with enterprise chatbot platforms that demand weeks of implementation and dedicated resources. Beyond the web widget, ChatME extends across multiple channels. A new voice agent answers phone calls and captures customer information in natural conversation. WhatsApp Business integration lets the same assistant handle inquiries on the messaging platform. A direct-link feature enables sharing via Instagram bio or QR code, eliminating the need for a website altogether. The bot responds in the visitor's detected language from a pool of 260 languages, making it relevant for multilingual audiences. Key capabilities include automatic lead capture through in-chat forms with custom fields, routing captured leads to your dashboard and email. An AI analytics feature lets users query metrics in plain language—asking what questions arrive most frequently on certain days. Integration with Google Calendar automates appointment bookings, reducing manual scheduling work further. The company targets small and medium-sized businesses explicitly, avoiding the enterprise market entirely. Pricing details remain limited in available materials, though the product offers a free tier with a 14-day trial on paid plans and no credit card required to start. Over 150 businesses currently use the platform. The approach strips away complexity intentionally, betting that SMBs would rather have a functional assistant than wait for a consultant-driven implementation. ChatME succeeds in its stated mission: meeting small business owners where they are, with tools that demand neither coding knowledge nor weeks of onboarding, yet deliver measurable customer service improvements across channels.
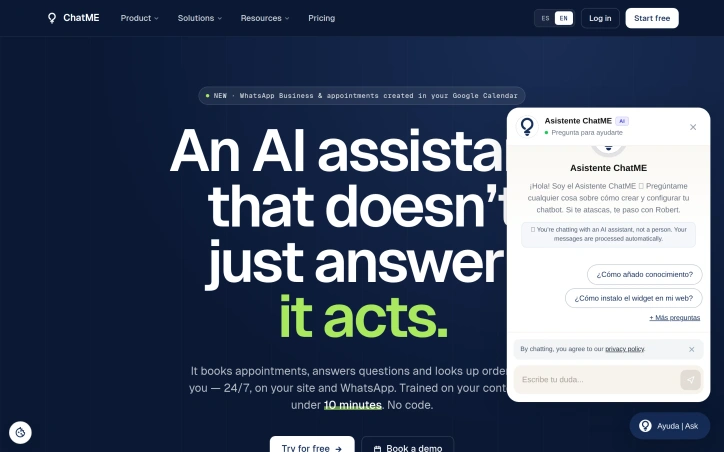
Finding the right financial product in Cambodia can be a daunting task, especially with numerous options available. The MoneyKH AI Tool is designed to simplify this process by engaging users in a conversational interface that recommends suitable financial products based on their specific needs. The tool is particularly useful for individuals seeking financial products such as savings accounts, loans, wallets, insurance, and remittance services. It is tailored to the Cambodian market, drawing on data from over 50 verified institutions across seven product hubs. What sets the MoneyKH AI Tool apart is its adaptive questioning process. Unlike traditional quizzes that follow a fixed script, this AI-driven advisor asks follow-up questions based on the user's input, allowing for a more nuanced understanding of their requirements. The tool then provides a personalized recommendation, explaining why a particular product is suitable and offering a link to compare it with other options on the MoneyKH platform. The AI Tool's capabilities are noteworthy. It covers a wide range of financial products and is backed by directly verified data from institutions, rather than relying on scraped marketing information. The conversation is free, and users do not need to provide their email address to receive a recommendation. The average conversation lasts around 60 seconds, making it a quick and convenient solution for those seeking financial guidance. Notably, the tool's conversational nature allows users to ask follow-up questions and delve deeper into their financial options. The developer's goal is to provide an intuitive and user-friendly experience, moving away from rigid, pre-scored matrices that fail to account for individual circumstances. The service is offered at no cost to the user, with the cost to use being explicitly stated as $0.
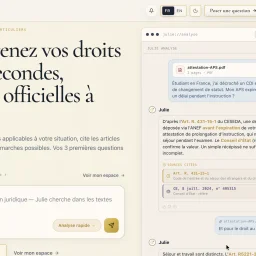
Accessing French law can be a daunting task for individuals, with a significant gap between the publicly available legal information and the ability to understand and apply it to personal situations. A new AI-powered solution bridges this divide by providing an intuitive interface to navigate the complexities of French legislation. The product is designed for individuals who need to understand their rights and obligations under French law, without requiring a legal background. It stands out for its ability to analyze user queries, posed in plain language, and provide relevant answers backed by official sources. Notably, the AI searches a vast corpus of up-to-date legal texts, including over 680,000 articles from Légifrance and 1.18 million court decisions. The results are delivered within approximately 20 seconds, with citations to the relevant laws and regulations. This ensures that users receive not only an answer but also the underlying legal basis for it. The product's accessibility is further enhanced by its pricing model, which includes a free tier for initial queries and one-time payments starting at €11.99 for more in-depth analyses. This approach avoids the need for a monthly subscription, making it more suitable for individuals with occasional or one-off legal questions. By providing direct access to verified, official sources and eschewing a subscription-based model, this solution offers a practical and user-friendly way for individuals to navigate the complexities of French law.
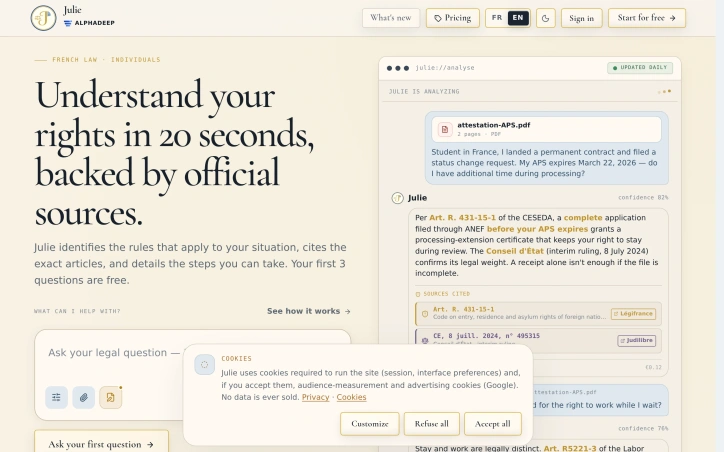

Seeking clarity without commitment, Tarovent offers a streamlined tarot reading experience that reduces the friction between curiosity and insight. The service addresses a specific frustration among tarot users: the need to determine whether a question requires a full reading before investing time and money into it. The product targets people navigating personal questions across relationships, career shifts, and daily decision-making. Rather than forcing users into lengthy readings or subscriptions, Tarovent allows anyone to pull a single card for free, answer a specific question, and decide whether deeper exploration makes sense. This low-stakes entry point works against the perception that tarot requires significant commitment or belief. What distinguishes Tarovent is its structured approach to question formation. Before selecting a spread, users articulate what they actually want to know rather than receiving generic readings. The interface offers entry points organized by context: love and relationship patterns, career pressures and transitions, crossroads requiring directional clarity, and daily mood checks. This specificity moves the reading away from fortune-telling theater toward directed self-reflection. The product depth mirrors this philosophy. Three spread options exist: the single card for immediate answers, the three-card spread for examining present dynamics, and the ten-card Celtic Cross for complex situations. Users who want to save readings and maintain a daily practice can create an account, receiving one free card daily while retaining full control over when and whether to pay for additional spreads. Transparency about tarot's limitations stands out in the interface itself. The product acknowledges that readings support personal guidance and self-reflection but cannot verify hidden facts, make promises, or reveal another person's private thoughts. This honesty counters the inflated claims that typically cloud tarot spaces, positioning the tool as genuinely useful rather than miraculous. The business model avoids subscription friction altogether. Users pay once per deeper reading if needed, keeping their relationship to the tool optional and exploratory. Combined with the daily free card for registered users, this approach removes pressure while sustaining revenue from people who find genuine value in the service. Tarovent ultimately succeeds because it respects user skepticism and autonomy, letting the experience justify itself through a single card rather than demanding upfront faith or commitment.
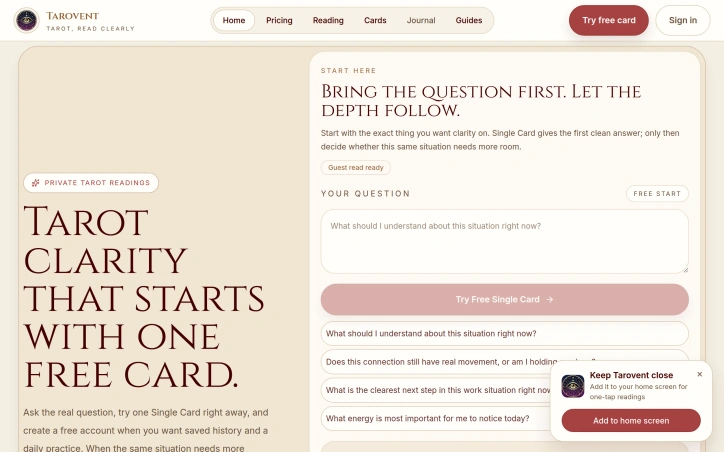

Capturing qualified leads from existing website traffic remains one of the biggest challenges for businesses of all sizes. Most websites squander visitor interactions—traditional contact forms create friction that drives prospects away, while generic chatbots fail to understand business context or identify which visitors actually warrant follow-up. Zappiq AI addresses this gap with a conversational AI that deploys directly onto any website in minutes. Rather than forcing visitors through forms, the chatbot engages naturally, learns the specifics of the business, and evaluates whether each prospect meets basic qualification criteria. When someone shows genuine intent and fit, the system captures their information and notifies the business immediately, eliminating the delays that plague traditional lead pipelines. The product shines in how it handles the operational side of lead capture. Every conversation gets stored with full context—visitor questions, responses, contact details, and lead sources all appear in one unified dashboard. This context eliminates the scattered note-taking and email chains that typically derail follow-up. The system scores leads by intent, fit, and urgency so sales teams know which prospects to prioritize. It also tracks attribution, showing which marketing channel or ad actually drove each lead, giving businesses clarity on where their traffic originates. The conversational quality matters here too. The AI generates responses that feel human rather than robotic, which shapes how visitors perceive the business itself. Zappiq AI also respects brand ownership—there's no "Powered by Zappiq" footer on customer sites, keeping the interaction feel native to the business. Third-party validation backs the product's positioning. It has earned a 91-plus Crunchbase score, the highest rating among AI agent platforms, and appears on multiple industry shortlists including Capterra, GoodFirms, and Product Hunt. These don't guarantee product-market fit, but they indicate sustained recognition within the lead generation tool category. The business model is straightforward: a 14-day free trial with 100 conversations included and no credit card upfront. This removes friction for businesses testing whether conversational lead capture actually works for their traffic volume and visitor types. Zappiq AI targets small to mid-market businesses tired of watching website traffic evaporate. The value proposition is direct—convert more of the people who visit you already. For companies with meaningful web traffic but weak lead capture infrastructure, it's worth testing.

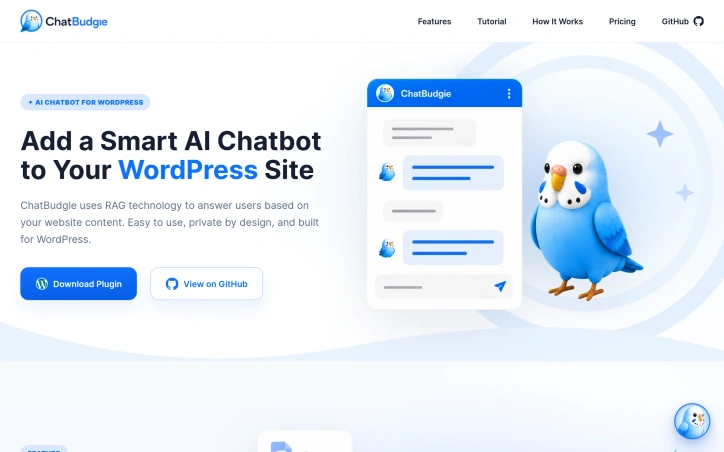
WordPress site owners constantly wrestle with the dual challenge of providing responsive customer support while keeping visitors engaged. Traditional AI chatbot solutions compound this problem by demanding complex API integrations, ongoing maintenance, and technical expertise that most website administrators lack. This plugin addresses that friction directly. Rather than pulling answers from the general internet, it uses retrieval-augmented generation (RAG) to ground responses in a site's actual content, delivering answers that are both accurate and contextually relevant to the business. This architecture shift eliminates the accuracy problems that come with generic AI responses while building customer trust through transparent sourcing. The implementation philosophy prioritizes simplicity over feature complexity. Setup takes minutes without requiring API key management or external service coordination. The chatbot automatically maintains its knowledge base as site content updates, removing the burden of manual retraining or version management that plagues other solutions. There is no server to configure, no backend infrastructure to oversee. Privacy by design is another differentiator. Because the system works within a WordPress site's own ecosystem and relies on its own content rather than third-party AI services, data handling remains under the site owner's control. This matters for businesses with privacy-conscious audiences or compliance requirements. The business model reflects this accessibility-first approach. Rather than adopting the software-as-a-service subscription model that dominates the chatbot space, the product uses one-time token purchases. A light-usage tier starts at $4.95 for five million tokens, with mid-range and high-volume options at $19.50 and $95 respectively. These purchases do not expire, and there are no hidden recurring fees. For WordPress operators with limited budgets or unpredictable chatbot usage, this removes the calculus of committing to monthly subscriptions. The product targets a specific underserved segment: small to medium WordPress sites that need support automation but lack the technical resources or budget for enterprise solutions. It does not promise to replace human support entirely, but rather to handle routine inquiries, reduce response time pressure on small teams, and create a more polished visitor experience. For that narrow use case, it presents a genuinely different approach to a common pain point.

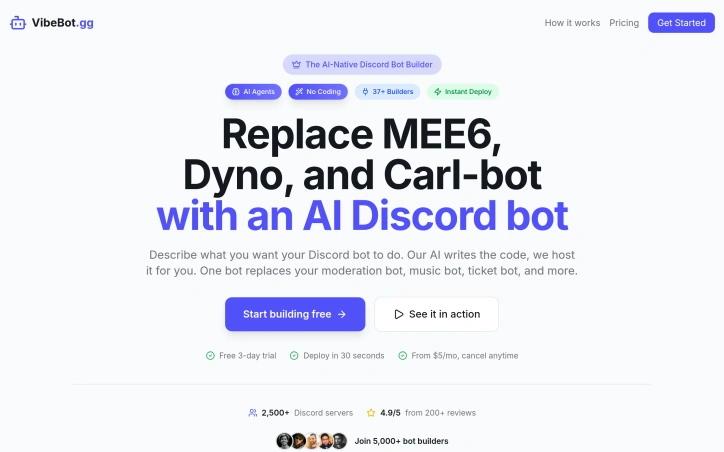
Creating and managing Discord bots can be a daunting task, especially for those without coding knowledge. VibeBot addresses this issue by providing a platform that allows users to build and deploy AI-powered Discord bots without requiring any programming expertise. The target audience is clearly Discord server administrators who struggle with managing multiple bots for various tasks such as moderation, music, and custom commands. What stands out about VibeBot is its innovative use of AI technology to simplify the bot creation process. Users can simply describe what they want their bot to do in plain English, and the AI will generate the necessary features and deploy the bot in under 30 seconds. This autonomous AI technology is a game-changer, enabling users to create complex bots with ease. The platform offers a range of key features, including AI moderation, music players, economy systems, and ticket handlers. The AI moderation agent is particularly noteworthy, as it can detect toxicity in real-time and take smart actions such as warning, muting, or banning users based on context. Additionally, VibeBot offers 18+ integrations, allowing users to connect their bot to various services. VibeBot offers a free 3-day trial, and its pricing starts at $5 per month, with the option to cancel at any time. The platform is hosted 24/7, ensuring zero maintenance and auto-scaling. With over 2,500 Discord servers already using VibeBot and a 4.9/5 rating from 200+ reviews, it's clear that the platform is delivering on its promise to simplify Discord bot creation. Overall, VibeBot is an impressive solution that is sure to appeal to Discord server administrators looking to streamline their bot management.

Users seeking more depth and personalization in astrology and tarot readings have a new option with Astic. The creator's motivation stems from a desire to move beyond generic, cookie-cutter horoscopes and offer users a more meaningful and tailored experience. Astic is geared towards individuals looking for introspective insights and guidance on various aspects of their lives, such as love, career, and personal growth. What stands out about Astic is its holistic approach, blending astrology and tarot archetypes to provide users with nuanced and multi-faceted readings. The platform's emphasis on user input and honest reflection creates a sense of agency and ownership over the reading process. The various reading options, such as open question, love compatibility, and year ahead, cater to different user needs and preferences. The reading process is transparent, with three distinct steps that prioritize user input, thoughtful analysis, and personalized interpretation. Users are encouraged to ask real questions and receive a customized report that is both informative and thought-provoking. The resulting readings are designed to be revisitable, with users able to save a representative image and revisit their insights at a later time. One user testimonial highlights the impact of Astic's readings, with Aria24 sharing a powerful emotional response to the hidden pattern section of her love compatibility reading. While pricing details are not explicitly stated, the overall tone suggests a product that is designed to provide lasting value to users. By focusing on the user's personal journey and offering a rich, interpretive experience, Astic distinguishes itself in the realm of astrology and tarot readings.

For individuals seeking clarity on life's complexities, TarotGuide offers a unique solution by providing AI-powered tarot readings. The platform caters to those navigating love, career, and personal growth, making ancient tarot wisdom accessible to a modern audience. By leveraging advanced technology, TarotGuide bridges the gap between traditional mysticism and contemporary needs. The founder's vision is to democratize tarot readings, making them available to everyone. What stands out about TarotGuide is its dual approach to tarot readings. The platform features two distinct AI-powered tarot readers, Moonlight and Stella, each specializing in different areas. Moonlight focuses on love, relationships, and emotional growth, offering empathetic guidance, while Stella provides insight into career, finance, and major life decisions with a more analytical approach. This distinction allows users to choose the reader that best suits their query. The platform offers a range of tarot spreads and readings, including one-card draws, love readings, and more complex spreads like the Celtic Cross. Users can explore the meanings of all 78 tarot cards, browsing through the Major and Minor Arcana. The interface allows for both manual card selection and auto-draw options, catering to different user preferences. Upon signing up, users receive 20 free credits, enabling them to try various readings without initial commitment. The platform performs over 10,000 readings daily, indicating a level of engagement and trust among its user base. While specific pricing details for additional credits beyond the initial free allocation are not provided, the variety of free and paid options suggests a freemium model, allowing users to experience the service before potentially purchasing more credits.

Managed access to AI infrastructure is a significant hurdle for students, entrepreneurs, and local teams looking to integrate AI into their projects. IPROG A.I addresses this challenge by providing a straightforward API that enables users to add AI capabilities to their systems without the need to operate their own AI infrastructure. The solution is designed with students and entrepreneurs in mind, simplifying the process of integrating AI into various applications, from school projects and research tools to business systems and customer support tools. What stands out about IPROG A.I is its practical approach to making AI accessible. It caters to users who need production-quality AI responses without the complexity of managing their own AI infrastructure. The API is designed to be developer-friendly, allowing users to create an account, obtain an API key, and start sending prompts and tracking token usage with ease. The product offers two main paths for integrating AI: a direct API for custom workflows and a hosted chatbot widget for websites. The API allows for full control over prompt design and response handling, making it suitable for integration into various systems, including web apps, POS, LMS, and CRM. The chatbot widget, on the other hand, enables users to embed a ready-to-use AI chatbot on their website with a single script tag, allowing visitors to ask questions based on uploaded business knowledge. Notably, IPROG A.I accommodates users who may not have access to credit cards by offering local payment options for topping up token credits. This feature, combined with its production-quality AI responses, positions IPROG A.I as a viable solution for students and entrepreneurs who want to build competitive projects. The service provides 5,000 free test tokens upon sign-up, allowing users to test the API before committing to a purchase.

Comparing token plans across various AI platforms can be a daunting task due to scattered and complex vendor documentation. AI Token Plan addresses this challenge by providing a centralized comparison of officially documented token plans, making it an invaluable resource for developers and businesses seeking to navigate the AI landscape. The platform stands out for its focus on official documentation, ensuring that the information presented is accurate and reliable. By normalizing data from various vendors into a single schema, AI Token Plan enables users to easily compare pricing, supported models, and tool compatibility across different platforms. The website currently tracks token plans from major players such as MiniMax, Tencent Cloud, Xiaomi MiMo, and Alibaba Cloud, providing detailed breakdowns of their respective plans, including pricing tiers, supported models, and compatible tools. For instance, users can see that MiniMax offers monthly and yearly tiers starting at $10/month and $100/year, while Tencent Cloud's personal plans begin at 39 RMB/month. Notably, AI Token Plan verifies the accuracy of its data, with each platform profile displaying the date of the last verification. This attention to detail underscores the platform's commitment to providing reliable information. While the platform does not disclose its own pricing or business model, its value proposition lies in simplifying the process of evaluating token plans, thereby saving users time and effort. By aggregating and normalizing data from various vendors, AI Token Plan empowers users to make informed decisions about their AI investments. Overall, AI Token Plan is a valuable resource for anyone seeking to navigate the complexities of AI token plans.

The need for accurate AI skills assessment is growing as companies increasingly integrate AI into their operations. Traditional methods of evaluating AI proficiency, such as multiple-choice quizzes, often fall short because they don't accurately reflect real-world AI usage. AISA addresses this issue by providing a conversational AI literacy test that measures how individuals actually use AI. What stands out about AISA is its interactive approach, engaging users in a twenty-minute conversation with Aisa, an AI interviewer that adapts to the user's role and experience. This conversation is evaluated in real-time by a second AI, which scores the user's strengths, gaps, and growth path across five dimensions. The result is a personalized report, including a persona classification, dimension scores, and a prioritized learning plan, culminating in a certificate that can be added to LinkedIn in one click. AISA's key features include its conversational assessment, a deep report that provides detailed insights into a user's AI skills, and a global AI skills leaderboard that allows users to compare their abilities with others. Additionally, AISA offers personalized AI coaching on WhatsApp, with daily lessons tailored to the user's assessment results. The platform is geared towards individuals looking to demonstrate their AI proficiency and towards teams and hiring managers seeking to assess their workforce's AI readiness. Notably, AISA provides its AI certification online for free, with no requirement for prior courses or training programs. The certification is derived directly from the conversational assessment, making it a unique and efficient way to validate AI skills. While AISA's pricing model for its additional features and services for teams is not explicitly detailed, the core AI certification assessment is free, making it an accessible entry point for individuals and organizations.

For traders seeking to make informed decisions across various markets, Noro AI offers a sophisticated artificial intelligence-powered trading assistant. At its core, the platform addresses the complexities of manual analysis and risk management, aiming to simplify the trading process. The target audience is serious traders operating in Forex, Crypto, Gold, and Stocks markets who require advanced tools to refine their trading strategies. One standout aspect of Noro AI is its comprehensive approach to market analysis, covering market structure, liquidity zones, and momentum to provide precise entry and exit signals. The AI-driven analysis is bolstered by features such as smart stop-loss and take-profit targets, risk management calculators, and trend analysis, which collectively enable traders to make data-driven decisions. The platform's ability to understand market context and detect liquidity zones further enhances its analytical capabilities. The platform's key features include instant alerts for potential trend reversals, ultra-low latency alerts for timely notifications, and continuous weekly updates to ensure maximum performance. Additionally, Noro AI prioritizes security and privacy, employing full encryption to safeguard user data. Noro AI operates on a tiered pricing model, with options ranging from a monthly subscription of $499 to a one-time lifetime payment of $7,499. The higher-tier plans, including the yearly and lifetime subscriptions, offer additional benefits such as 1-on-1 onboarding sessions, deep-dive weekly reports, and private wealth consultation. For select plans, professional account management is available, where expert AI and human traders manage the user's capital for optimal returns, with a profit-sharing model that aligns the interests of the user and the management team.

Caring for plants can be a daunting task, especially for those new to the world of indoor gardening. Forgetfulness and uncertainty often plague plant enthusiasts, leading to neglect and a lack of confidence in their ability to nurture their plants. Virido addresses this issue head-on by providing a comprehensive solution for plant care. The app is designed for anyone looking to simplify the process of caring for their plants, regardless of their level of experience. What sets Virido apart is its reliance on AI technology to power its plant identification and care features. By taking a photo of a plant, users can instantly receive information on the plant's species, care requirements, and watering schedule. The app's AI-powered expert also offers personalized advice and diagnoses potential issues, providing users with a trusted resource for all their plant care needs. The app's features are geared towards making plant care as seamless as possible. Users can set up smart reminders to ensure they never forget to water or tend to their plants. For more advanced users, the Pro version unlocks additional tools and features, including unlimited plant identifications and access to a comprehensive plant library. For those looking to take their plant care to the next level, Virido offers a robust set of capabilities. While the specifics of the pricing model are not entirely clear, the distinction between the standard and Pro versions suggests that the app operates on a freemium model, with certain features reserved for paid users. Overall, Virido has the potential to be a valuable resource for plant enthusiasts, providing a one-stop-shop for all their plant care needs.

Budget hemorrhage is the silent killer of every AI initiative that grew faster than the finance spreadsheet. PromptUnit attacks that problem head-on: it shows engineering teams exactly where their tokens bleed cash and then patches the wound without touching a line of code. Seed-stage startups accruing five-figure OpenAI bills and mid-market companies trying to rein in a mosaic of LLM providers finally have a single valve to turn. The product deploys like an analytics layer that refuses to stay passive. Once you swap one environment variable—yes, truly one—the proxy begins logging every request in “shadow mode,” generating real-time dashboards that break cost, latency and usage down by model, feature and even individual prompt type. After a couple of weeks it presents an itemized forecast: keep current behavior and pay $12,400 next month, or let PromptUnit route intelligently and pay $6,960 instead. Enablement happens with a toggle, revertible just as fast. Routing decisions are explained in English next to every call rather than buried in an inscrutable algorithm. If GPT-4o-mini can hit the quality bar for a routine summarization task, the dashboard explicitly credits the $0.07 saved; if a complex code-generation request stays on GPT-4o, the rationale is right there. Automatic failover means the proxy never becomes a single point of failure—it steps aside the moment it stumbles. GDPR residency controls and guarantees that your prompts never feed anyone else’s training set complete the enterprise hygiene checklist. PromptUnit is chargeable only on verified savings, skimmed at a flat 20% of the delta. No savings, no invoice; turning it off permanently is always one click away. That alignment of profit motive and customer thrift turns loose change into an obvious install, not another procurement debate.

Indie hackers reinvent QA every Thursday by typing “npm test” and calling it a day, then wonder why no one sticks around after launch. CanIShip extracts that wishful thinking and submits the product to the same nine-point safety regime merchants use when their cargo crosses an international border. You copy your URL, write one sentence about what the app does, and in fifteen minutes get back a thumbs-up or a red stop sign alongside detailed receipts. The service runs its full battery on every pass: functional tests that drive flows with Playwright, axe-core accessibility scans against WCAG 2.1 AA, Lighthouse tight core-web-vitals benchmarks, header audits drawn from OWASP checklists, network link validation, mobile viewport diagnostics at 375 px, plus an extra layer that flags business or regulatory red flags such as illegal products, fake engagement, or platform policy marshes. Nothing to install and no access tokens traded away; the runner just needs the publicly reachable site. Three inspections per month cost exactly zero euros, and after that the published plan shows only paid tiers without surprises. Founders who equate “ship” with “upload” receive instead a short essay explaining why their little rocket is about to explode—or why it is cleared to leave orbit. Ultimately useful only for web front-ends today, yet within that narrow corridor the breadth is unmatched: one submission produces data a full QA team would normally cobble together from five separate tools, spreadsheet gymnastics, and at least one collaborator whose eyes glaze over at pytest. Solo builders shipping AI-generated code will understand exactly what still needs human editing, and they will understand it before the Hacker News headline goes live.


Developers regularly encounter codebases written in unfamiliar patterns, legacy languages, or architectures outside their expertise—and the gap between code literacy and actual understanding can significantly slow productivity. ExplainThisCode targets this friction by providing AI-generated explanations of code snippets adapted to individual skill levels, eliminating the need to hunt through documentation or rely on colleagues for clarification. The product's core strength lies in its recognition that code comprehension isn't one-size-fits-all. Rather than generating a single explanation, it tailors output to the user's proficiency: beginners receive analogies and step-by-step walkthroughs, while experienced developers get architectural context and complexity analysis. This approach, powered by GPT-4 and Claude, treats understanding as a variable problem rather than a commodity feature. The tool supports eighteen programming languages, reducing barriers for polyglot teams. The interface emphasizes frictionless experimentation. Users can paste code, upload files, reference GitHub repositories directly, or integrate via API without signing up—a deliberate choice that prioritizes discovery over gatekeeping. Explanations stream token-by-token as they generate, providing immediate feedback rather than forcing users to wait for complete responses. The product bundles explanation depth (quick summaries through comparative analysis) with analysis modes focused on security vulnerabilities and performance bottlenecks, making it pragmatic for code review and auditing workflows. The API pathway is notable. Rather than positioning itself as a chat interface for code (a territory crowded with general-purpose AI assistants), ExplainThisCode frames itself as a purpose-built microservice that teams can embed into existing development tools—an architecture that acknowledges where code explanation actually happens: in IDEs, documentation platforms, and CI/CD pipelines, not in dedicated browser tabs. The pricing structure reflects this positioning. A free tier caps requests at twenty per day, sufficient for casual exploration but clearly designed to convert regular users. The Pro plan at nineteen dollars monthly grants five hundred requests daily and unlocks API access, supporting both individual developers and small teams. Enterprise contracts accommodate large organizations with custom limits, team SSO, and deployment flexibility including self-hosted options. The main limitation is scope: the tool excels at explaining what code does and highlighting potential issues, but doesn't appear to help users *refactor* or *improve* the code in place. It remains fundamentally an explanatory tool, not a development partner. That's a rational constraint—it keeps the product focused—but it leaves a logical follow-on workflow unaddressed.

Reverse image-to-prompt conversion is becoming a critical workflow for AI artists, and GetImageToPrompt addresses this directly. The tool analyzes uploaded images and generates detailed text prompts optimized for popular generative AI models like Midjourney, Flux, DALL-E 3, and Stable Diffusion. For creators working across multiple AI platforms, this eliminates the friction of manually describing visual references or reverse-engineering prompts from images. The product targets four distinct user segments. AI artists and character designers use it to create reusable, consistent prompts across different models. Visual designers convert reference images into structured prompts for creative workflows. Marketing teams extract visual descriptions for campaigns and social media. Developers and researchers leverage the tool's JSON output for programmatic access and analysis. What sets GetImageToPrompt apart is its privacy-first positioning. Images are processed in real-time but never stored on servers, addressing the primary concern creators have when uploading visual assets to online tools. The free, unlimited access model removes friction entirely—no credits system, no sign-up requirement, no usage caps. This approach prioritizes accessibility over monetization. The feature set reflects practical needs in prompt engineering. Beyond basic image analysis, the tool extracts subject details, compositional elements, lighting effects, and artistic style tags. An OCR feature flags text elements within images, useful for designs containing typography. The prompt override functionality lets users modify outputs with natural language instructions like "make the dress yellow" or "add cinematic lighting," enabling quick iterations without re-uploading. Output flexibility matters for different workflows. The JSON prompt mode delivers structured data suitable for developers and advanced workflows, while standard text output serves artists working directly with image generators. The product also showcases gallery examples across anime, cinematic, and photorealistic styles, demonstrating consistency across output types. The website mentions optimization for specific model versions like Midjourney v6.1 and Flux 1.1 Pro, suggesting the tool maintains awareness of evolving model strengths and syntax preferences. This targeted optimization reduces the trial-and-error cycle many creators face when adapting prompts between platforms. The core value proposition is straightforward: accelerate the creative reference-to-prompt conversion process while protecting user privacy. For a market where AI-generated content creation is becoming commonplace, a free tool that removes both technical and trust barriers fills a genuine gap.

Switching between ChatGPT, Gemini, Grok, and half a dozen other AI apps takes a toll on productivity and your wallet. Omni AI consolidates access to more than 20 leading AI models into a single iOS and Android application, positioning itself as the one-stop solution for users who want to leverage multiple AI systems without maintaining separate subscriptions. The app's core appeal is straightforward: rather than juggling tabs or apps, users can access GPT-5.2, Claude Sonnet 4.5, Grok 4.1, Gemini 3, DeepSeek R1, Mistral Large 3, Llama 4 Scout, Perplexity Sonar, and others all in one place. The real differentiation comes in how the app handles model selection. Omni AI displays the strengths and optimal use cases for each model, helping users understand which one to choose for coding, writing, math, research, or creative tasks. More importantly, the app allows mid-conversation model switching, letting users compare outputs directly without starting over. Beyond chat, Omni AI bundles image generation, video creation, and AI-powered web search into the same interface. Cross-device sync means conversations and preferences carry across phones and tablets, while organizational features like chat folders and specialized "expert AI assistants" for specific tasks bring structure to what could otherwise feel chaotic. The numbers suggest adoption is gaining traction. The app has reached 200,000 downloads, maintains a 4.5-star rating, and has processed over 175 million messages. These figures sit well within the range of a serious mobile application gaining early momentum, though still short of mainstream penetration. Pricing is approachable. The app is free to download with a freemium model; premium plans start at $5.99 per week, $9.99 per month, or $59.99 per year. This positions Omni AI as cheaper than maintaining subscriptions to OpenAI, Google, and xAI separately, though the exact cost-benefit depends on which models a user actually needs and how often they access premium features. For developers, researchers, writers, and anyone who regularly switches between different AI models, Omni AI removes friction. The real test will be whether the consolidated experience actually improves workflow quality or simply trades one form of switching—between apps—for another.