Vehla
Streamlining workflows on Mac devices is a daunting task, especially when users have to juggle multiple utilities to acc...
Best Design & Creative Startups & Tools
Recently Listed
97 launches
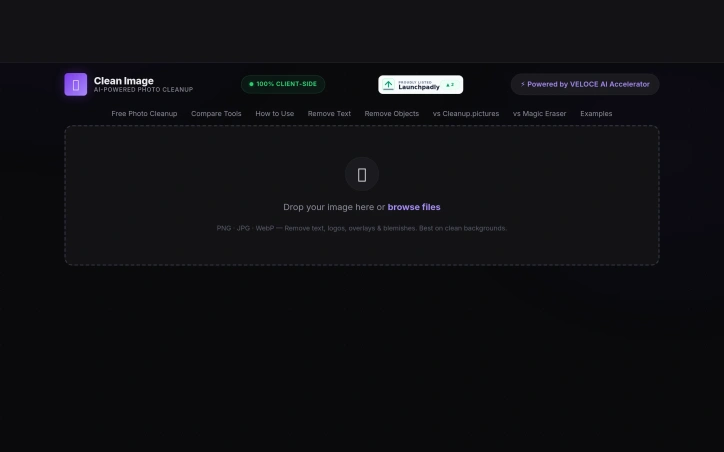
Privacy concerns about cloud-based photo editing have driven innovation in browser-based alternatives, and Clean Image addresses this directly by processing images entirely on the user's device. The tool targets anyone who needs to remove unwanted elements from photos—text overlays, logos, timestamps, blemishes, and stray objects—without uploading their files to external servers. The standout feature is the privacy-first architecture. All processing runs locally through ONNX Runtime and WebAssembly, meaning images never leave the browser. The application uses the OpenCV LaMa neural network to reconstruct areas where users paint over unwanted content, relying on surrounding pixels to generate replacements. This approach works particularly well on clean backgrounds and straightforward removal tasks like text or logos. The user experience emphasizes simplicity. The interface follows an intuitive brush-and-paint metaphor: users tap to aim and paint over elements they want removed, then trigger the erasure. Undo and clear options let them refine before downloading the result. Performance addresses one of the common friction points with local AI tools. The neural network model requires a one-time download of approximately 89 megabytes, which caches in the browser. After this initial load, subsequent uses deliver instant processing with zero data usage, removing the bandwidth burden of repeated cloud uploads. Clean Image supports common image formats including PNG, JPG, and WebP, accommodating most typical photo libraries. The before-and-after comparison feature lets users validate results before saving. The primary limitation stems from its design strength: effectiveness depends heavily on background consistency. Complex, busy backgrounds present challenges for the reconstruction algorithm, which is typical of inpainting-based approaches. Users seeking to remove unwanted content from highly textured or diverse backgrounds would encounter diminishing returns. Clean Image fills a genuine gap for privacy-conscious users who previously had to choose between convenience and data protection. For straightforward removal tasks on suitable images, the local processing approach delivers practical value without sacrificing privacy. The tool serves professionals and casual users alike who prioritize keeping their photos local while leveraging modern AI capabilities.

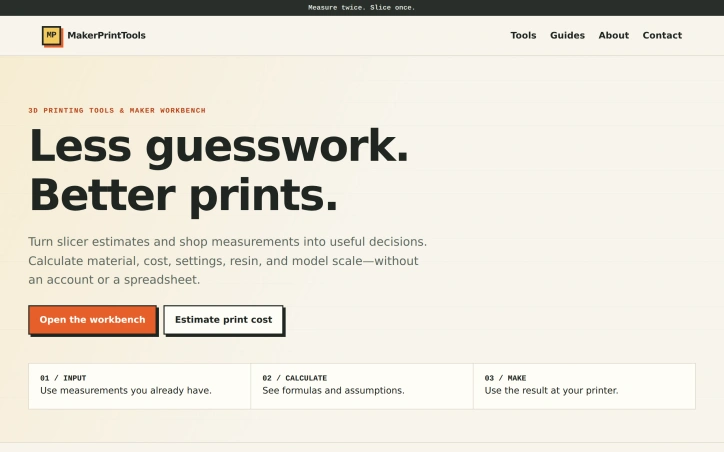
Makers and 3D printing shops waste time converting slicer estimates into real-world decisions through spreadsheets or trial-and-error. MakerPrintTools replaces that friction with a collection of specialized calculators designed for shop-floor problems, each combining measurements you already have into actionable results. The platform targets anyone running a 3D printing operation—whether a one-person hobby shop or small production facility—who needs to calculate costs before quoting jobs, verify that a printer can actually achieve a design's settings, or estimate material waste. No account is required, so users can jump directly from measuring part geometry to making confident decisions. What distinguishes the product is its deliberate scope. Rather than a generic calculator, each tool solves a specific question: How much does this print actually cost? How many grams of filament does a particular length represent? Will my hotend flow capacity handle these settings? This focused design makes each calculator faster and more useful than generic spreadsheets. The platform also explains its math—showing formulas and assumptions—so users understand the reasoning behind every result. The toolkit spans the full production cycle. Cost calculators combine filament consumption, electricity usage, labor time, machine wear, and failure allowance into practical job pricing. Filament converters switch between meters and grams using actual material density. A volumetric flow checker validates that hotend capacity matches intended print parameters. Geometry tools handle model scaling and build volume constraints. Planning tools look beyond individual prints to estimate total material use, support requirements, and the production volume needed to break even on setup work. The product positioning emphasizes transparency over convenience. There's no cloud storage, no project management, no growth features—just clear math applied to shop measurements. The design assumes makers already know what they're measuring and what they'll do with the results; the calculators simply eliminate error and guessing from the conversion. This approach creates a practical, single-purpose tool that integrates into existing workflows rather than requiring process change. For small and mid-scale 3D printing operations, that efficiency compounds across hundreds of decisions. The frictionless entry point—no login, no free trial cutoff, no marketing emails—removes barriers to trying calculators that genuinely answer shop questions.
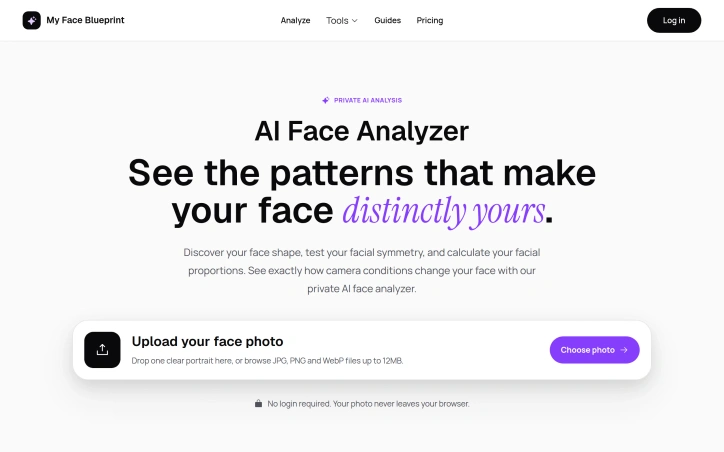
Understanding facial features has traditionally been either superficial (makeup tips) or clinical (orthodontic assessment). My Face Blueprint positions itself between these poles, offering structured analysis of facial structure, symmetry, and proportions through an AI analyzer that runs entirely in a user's browser. The problem the tool addresses is twofold. First, many people lack a clear framework for understanding their own facial geometry beyond casual observation. Second, camera distortion creates persistent confusion; a wide-angle selfie makes cheeks appear broader while a longer-distance camera narrows the face. My Face Blueprint attempts to solve both by separating true facial structure from photographic artifacts. The product delivers eight distinct analyses from a single portrait: face shape classification, symmetry testing, golden ratio calculations, canthal tilt measurement, jawline rating, eye shape detection, hunter eyes assessment, and facial width-to-height ratio computation. These feed into a comprehensive Face Blueprint that synthesizes cheekbone width, jawline angle, eye spacing, and facial thirds into a visual map. The tool includes practical guidance on proper camera distance, lighting, and angle to capture more accurate portraits. Privacy receives prominent treatment. Photos never leave the browser, no login is required, and results remain accessible without payment. The product targets photography enthusiasts, people interested in facial structure, and anyone curious about how camera conditions distort their appearance rather than those seeking cosmetic improvement or medical assessment. The business model relies on a one-time $7.99 purchase for premium insights, which expands the free analysis with a downloadable PDF report and high-resolution keepsake card. The credit system (100 credits per purchase, with complete blueprints consuming 10) suggests room for additional premium analyses. Notably, free analysis remains functional and permanently visible, reducing friction for trial and exploration. The tool's positioning avoids cosmetic or self-esteem framing, instead emphasizing technical understanding and practical photography guidance. For those genuinely interested in facial geometry rather than vanity metrics, My Face Blueprint offers structured, accessible analysis without data harvesting or mandatory subscriptions.

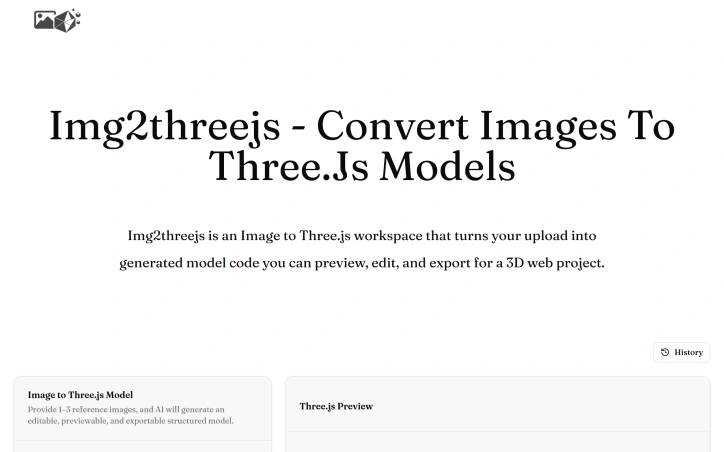
Developers and designers frequently face friction when translating visual concepts into Three.js scenes. Creating geometry, materials, lighting, and camera configurations from scratch for every new project adds setup overhead that detracts from the creative work itself. This is the core problem that Image to Threejs addresses. The product automates the initial translation step by accepting image uploads as visual references. Users provide one to three reference images, and the platform's AI generates Three.js code structured to match the visual content. Rather than claiming pixel-perfect reconstruction, the creators acknowledge that a single image cannot capture all depth details and hidden surfaces. This honest framing positions the generated model as an editable starting point rather than a final deliverable. The workflow keeps this pragmatic philosophy throughout. After generation, users encounter an interactive 3D preview where they can inspect the AI-generated model in real time. From there, they can directly edit the code, refine geometry and materials, and iterate visually without the traditional back-and-forth between reference images and development environments. Once satisfied, the model exports for integration into Three.js projects, websites, or interactive experiences. What distinguishes Image to Threejs is its integration of these typically separate concerns into one cohesive interface. Rather than managing uploaded images separately from code editors and preview tools, users stay within a single workspace. This reduces context switching and the friction of coordinating multiple tools. The target audience spans developers seeking faster iteration on 3D web projects, designers who want to prototype interactive models without deep Three.js expertise, and creative technologists exploring generative approaches to 3D design. The product makes sense for those building product visualizations, website experiences, or experimental interactive content. The core value proposition is straightforward: eliminate the tedious foundation-building phase of Three.js development. By generating working code and a realistic first draft from an image, the platform lets users reach the refinement stage faster. This appeals to teams that prioritize velocity and to individuals who want to experiment with 3D web concepts without significant setup investment. No pricing information appears in available materials, leaving the business model's specifics unclear. What is clear is that Image to Threejs solves a real friction point in visual web development, offering a practical bridge between design intent and executable Three.js code.

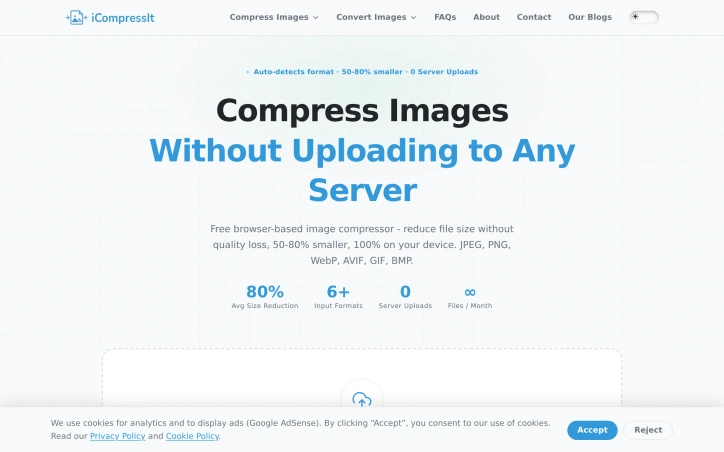
Shrinking image file sizes while maintaining visual quality has long frustrated content creators, developers, and everyday users handling photo libraries. iCompressIt solves this by running the entire compression process inside the browser, eliminating the privacy risks and friction of uploading sensitive photos to remote servers. The product targets anyone working with images: content creators managing photo libraries, developers optimizing web properties, freelancers handling client assets, or individuals reclaiming storage space. What distinguishes iCompressIt is its commitment to on-device processing. Every compression happens locally through the Canvas API, meaning images never leave your device. This architecture simultaneously solves privacy concerns and removes the need for account creation or subscription management. The compression engine runs multiple strategies across formats simultaneously. For JPEGs, it tests both JPEG and WebP pipelines and returns whichever produces the smaller file. The tool auto-detects input format and applies the most aggressive compression strategy for that type, removing guesswork from optimization. Results typically achieve 50 to 80 percent file size reduction. iCompressIt handles JPEG, PNG, WebP, AVIF, GIF, and BMP formats, with batch processing that lets users drop dozens of images at once and download results as a single ZIP file. The product includes a size-safety guarantee: output never exceeds the original file size, and if compression offers no benefit, the tool returns the unchanged file. Users compress unlimited files monthly with no daily quota, file size cap, or watermarks. The business model prioritizes sustainability through simplicity. The tool is free forever with zero account requirements and no upload limits. A single ad slot provides monetization, and the absence of paywalls, subscription tiers, or storage restrictions positions iCompressIt as accessible freeware in the image optimization space. The product's main strength is removing friction from a routine workflow while addressing legitimate privacy concerns. By prioritizing on-device processing and batch functionality, iCompressIt appeals to individuals seeking a straightforward compression tool and to professionals managing recurring image workloads alike.

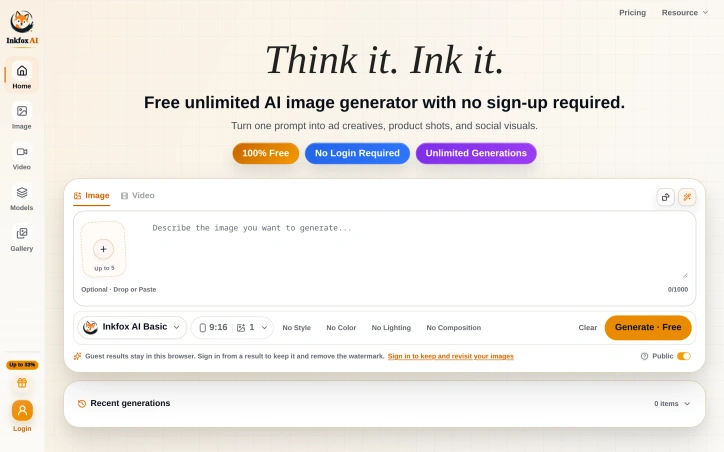
The demand for AI-generated images has surged across various industries, but existing solutions often come with limitations such as restricted generation capabilities and mandatory sign-ups. Inkfox AI addresses these pain points by offering a free, unlimited AI image generator that doesn't require users to create an account. At its core, the platform is designed to simplify the process of creating diverse visuals from a single prompt. Users can input their desired image description and generate multiple ad creatives, product shots, and social media visuals. The absence of a sign-up requirement makes it instantly accessible, allowing users to start generating images right away. One of the standout features of Inkfox AI is its ability to produce unlimited generations without charging users. The platform provides options to customize the output by selecting between image and video, and it allows for some level of control over the generation process through parameters such as style, color, lighting, and composition. However, users should be aware that results generated without signing in are confined to the current browser session and will include a watermark. Users who don't sign in will have their results stored locally in their browser, and these results will be watermarked. Signing in offers the benefit of retaining generated images and removing the watermark. The simplicity of the generation process, coupled with the flexibility to create a variety of visuals, makes Inkfox AI an attractive option for users seeking to leverage AI-generated imagery. Inkfox AI is notable for its straightforward, no-frills approach and commitment to being 100% free with unlimited generations. This business model is explicitly stated, with no additional pricing tiers or caveats mentioned on the website. Overall, Inkfox AI is well-suited for individuals and businesses looking for a hassle-free, cost-effective solution to generate AI-based visuals.
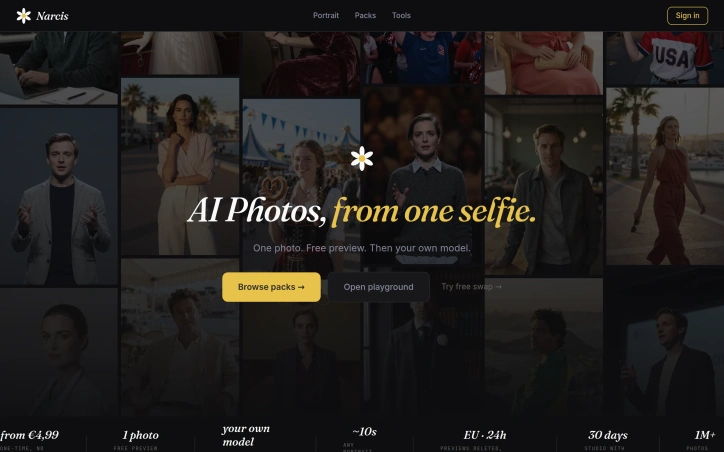
In today's digital age, creating high-quality, professional photos can be a challenge for individuals and businesses alike. Narcis.ai addresses this issue by providing an innovative solution that leverages AI to generate realistic photos and swap faces onto existing images. The platform is geared towards individuals seeking professional headshots, creative portraits, or artistic images for personal branding, social media, or corporate profiles. With Narcis.ai, users can create customized photos that are tailored to their needs, without the need for expensive photoshoots or extensive technical expertise. What stands out about Narcis.ai is its emphasis on producing authentic, realistic images that are comparable to genuine photographs. The AI technology is trained to avoid the typical "AI look" often associated with generated images, ensuring that outputs are of high quality and visually appealing. Additionally, the platform prioritizes user privacy and data security, processing images on in-house EU-based servers and deleting selfies within 24 hours. The AI Photo Generator and Face Swap features are the core offerings of Narcis.ai. The AI Photo Generator allows users to upload a selfie and describe the desired style or scene, generating a new image in approximately 20 seconds. The Face Swap tool enables users to seamlessly replace their face onto any existing photo in about 10 seconds. Both features are browser-based, eliminating the need for downloads or subscriptions. Narcis.ai operates on a one-time payment model, with users able to purchase individual packs for €4.99 or €9.99, which include 30 days of unlimited portrait generation through the Studio feature. This flexible pricing structure makes the platform accessible to a wide range of users, from individuals seeking creative portraits to businesses requiring professional headshots.

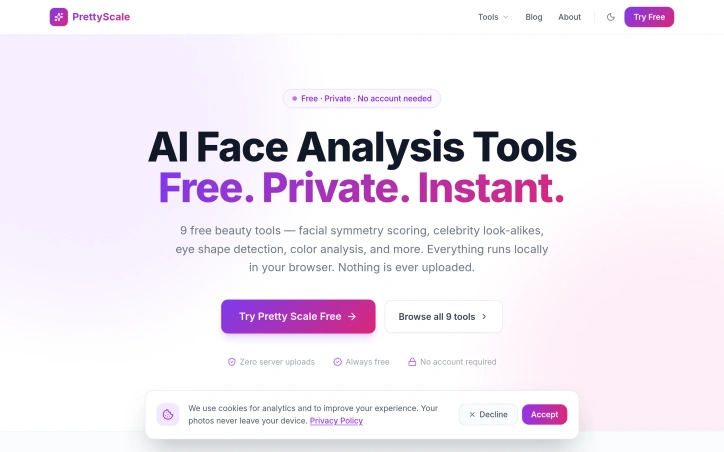
In the realm of beauty analysis, concerns about privacy often hinder users from exploring their features in-depth. To address this, a novel solution has emerged, prioritizing user privacy while providing a suite of AI-powered beauty tools. The driving force behind this innovation is the need for a secure and confidential platform where users can analyze their facial features without compromising their personal data. By ensuring that all analyses run locally within the user's browser, the solution effectively eliminates the risk of sensitive information being shared or stored. What stands out about this product is its commitment to maintaining user privacy while delivering a comprehensive range of beauty analysis tools. The absence of server uploads and data collection mechanisms underscores this commitment. Notably, the AI-driven tools are diverse, encompassing facial symmetry scoring, celebrity look-alikes, face shape detection, and color analysis, among others. Key features worth highlighting include the ability to analyze 468 facial landmarks for precise assessments and the availability of personalized style tips and recommendations based on the analysis. The product offers nine distinct tools, each designed to cater to different aspects of beauty analysis, from determining face shape and eye shape to estimating age and identifying the most flattering colors. The product is touted as being free forever, with no hidden costs or account requirements, making it accessible to a wide range of users. By forgoing a traditional revenue model that relies on user data or subscription fees, the developers have successfully created a unique value proposition centered around privacy and accessibility.

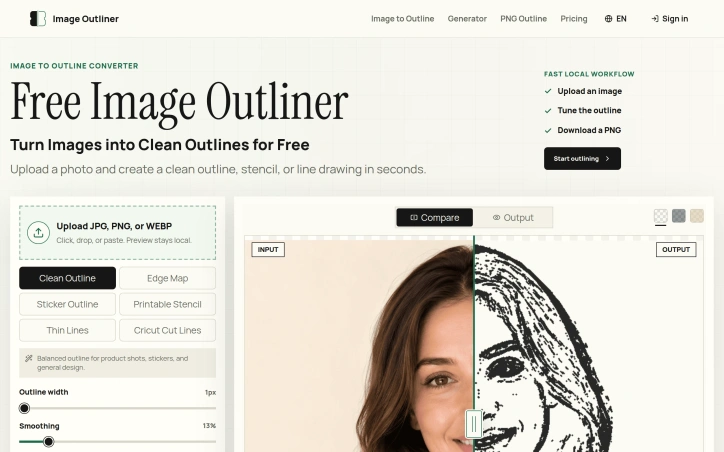
Converting images into clean, usable outlines is a task that has long plagued creatives, requiring either expensive design software or tedious manual tracing. Image Outliner addresses this issue head-on, providing a straightforward solution for individuals looking to transform their photos into crisp line drawings. The tool is designed with a specific user in mind: crafters, designers, and artists seeking to create outlines for various applications such as Cricut projects, stickers, tattoo stencils, or coloring pages. It delivers on its promise by offering a range of output styles tailored to different use cases, including clean outlines, printable stencils, and Cricut cut lines. What stands out about Image Outliner is its commitment to a fast and private workflow. The entire process, from uploading an image to downloading a PNG, occurs locally in the browser, ensuring that users' data remains private. The tool also provides a range of controls to customize the output, including stroke width, smoothing, and threshold, allowing users to fine-tune their outlines to suit their needs. Key features include the ability to upload various image formats, preview and adjust the outline in real-time, and download transparent PNGs. For users requiring a more polished result, an AI Enhance feature is available, although this comes at a cost, with one credit being used per enhancement. The product's focus on practical output is evident in its design, with features such as edge map previews and Cricut-ready outlines demonstrating a clear understanding of the needs of its target users. Overall, Image Outliner offers a valuable solution for creatives looking to simplify the process of creating clean, usable outlines from their images.
Creating stunning visuals from text prompts just got a lot easier, thanks to a innovative AI-powered solution designed specifically for creators. The problem it tackles is the tedious and time-consuming process of crafting complex prompts to achieve desired results, freeing up artists to focus on their craft. What stands out about this product is its ability to understand intent in any language, allowing users to simply write in plain language and receive high-quality images and videos on demand. The AI engine is capable of delivering diverse and unique outputs, making it an ideal tool for those who need rapid iterations and varied results. Notably, the product boasts a range of key features, including the ability to generate four variations in seconds, making it perfect for tight deadlines. It also offers style references, video generation, and more, built right in. Additionally, users can integrate the product into their workflow via a full REST API with comprehensive documentation and examples. The pricing model is straightforward, with a pay-as-you-go approach that eliminates forced subscriptions. Users can choose from a range of plans, including a novice pack with no commitment, or higher-tier plans with varying levels of support and credits. All plans include full commercial rights, with no hidden fees, and users can cancel anytime. With over 600 creators worldwide already trusting this product, it's clear that it's making a significant impact in the creative community. By simplifying the process of creating stunning visuals, this AI-powered solution is empowering artists to bring their ideas to life quickly and easily.
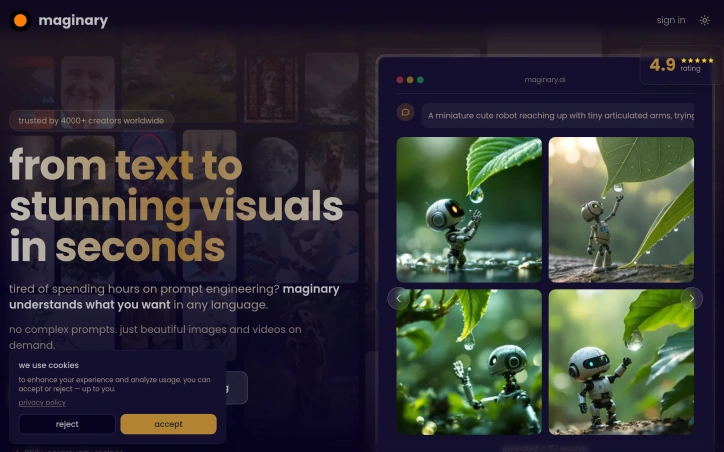

Creators working with AI-generated media face a fragmented workflow. After spending time generating images and videos across various AI tools, they must jump between multiple applications to organize, compare, and present their results. VidBoards consolidates this repetitive context-switching into a single, focused application designed specifically for reviewing and presenting generated batches. The product targets AI creators actively using generation tools like ComfyUI, Automatic1111, Stable Diffusion, and similar platforms. Rather than building yet another creation tool, VidBoards solves the problem that comes after generation: managing outputs efficiently, comparing results systematically, and presenting sequences without leaving the application. What distinguishes VidBoards is its philosophical foundation. The application operates entirely locally without subscriptions, accounts, or cloud services. It reads embedded metadata directly from generated files, eliminating manual documentation burden. This approach appeals to creators who prioritize privacy and control over their workflow. The interface centers on an infinite canvas where users arrange videos and images freely using standard gestures: middle-mouse panning, scroll-wheel zooming, and optional snap-to-grid alignment. Multiple boards support unlimited cards per project, saved as lightweight .vdb files. The architecture remains deliberately simple, keeping users focused on their media rather than fighting interface complexity. The shared timeline feature represents the core innovation. A single scrubber syncs all videos to the exact same frame simultaneously, enabling instant comparison across dozens of clips. Rather than opening multiple players and mentally tracking differences, creators see frame-by-frame variations across all takes at once. This directly addresses the time spent hunting for optimal shots. Sequence Mode transforms the application into a presentation tool. Users activate a full-screen overlay, arrange clips in order, and play them back-to-back like a showreel. Auto-advance between items and keyboard controls eliminate the need to export to external presentation software. Supporting tools include batch operations through multi-select, quick media controls for simultaneous playback or looping, and support for PNG, JPEG, WebP, MP4, and MKV formats. The application also handles metadata from multiple AI generation tools seamlessly. The pricing model is unambiguous: free, forever, with no subscription, no account requirement, and no cloud dependency. For a creator-focused tool addressing a specific workflow bottleneck, VidBoards demonstrates disciplined product design aligned with its audience's actual needs.
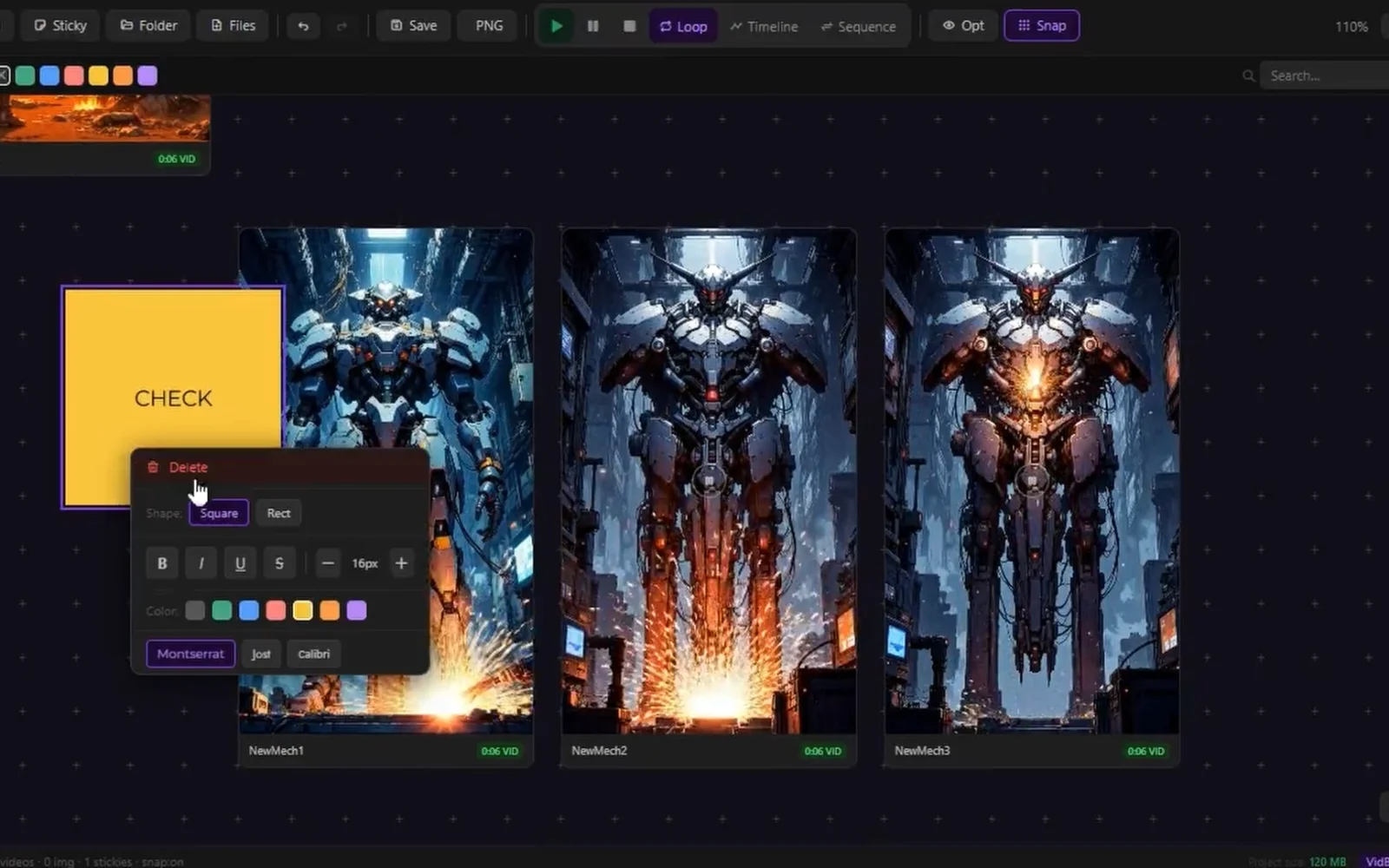

Creative professionals and businesses struggling to generate high-quality visual content at scale now have access to a streamlined AI image generation platform that prioritizes both speed and ease of use. GeniusAI targets content creators managing production timelines, marketing teams running campaigns, and developers building AI-powered applications, offering a tiered approach that accommodates different user needs and budgets. The platform distinguishes itself through deliberate simplicity. Rather than overwhelming users with endless customization options, GeniusAI presents a three-step workflow: select from preset AI models and styles, describe what you want in natural language, and generate the image. This straightforward approach appeals to users without technical AI expertise while providing enough control for professionals seeking consistency across projects. The product features image generation with multiple model variants, photo editing tools, and image upscaling capabilities. Prompt enhancement automatically improves user descriptions before generation, reducing the friction of crafting perfect prompts. Teams can collaborate within a shared workspace, and all tiers include commercial licensing, removing legal uncertainty around using AI-generated content for business purposes. For developers, an API enables integration with existing workflows and the ability to enforce brand guidelines programmatically. GeniusAI's pricing structure reflects its market positioning. The entry-level Genius Creator tier at ten dollars monthly offers 700 monthly credits sufficient for casual creators, with images up to 896 by 896 pixels and access to eight preset styles. The Genius Studio tier at thirty-five dollars monthly jumps to 3,000 credits and increases resolution to 1024 by 1024 pixels while unlocking all 21 available styles. The Genius Pro tier at forty-five dollars monthly adds 5,000 monthly credits, extends creation history to unlimited, and includes twenty-four hour priority support. Each tier supports instant regeneration and full-size downloads. The generation process emphasizes speed; the platform can produce images in seconds rather than minutes, a meaningful advantage for professionals with tight deadlines. The inclusion of multiple generation modes allows users to balance output speed against visual polish depending on project requirements. The platform's positioning emphasizes both accessibility and professional capability, suggesting it serves as a bridge between casual users discovering AI-generated imagery and teams deploying it as part of their production workflows. The combination of competitive pricing, commercial licensing, and team features positions GeniusAI as a practical choice for businesses integrating generative AI into existing creative operations.
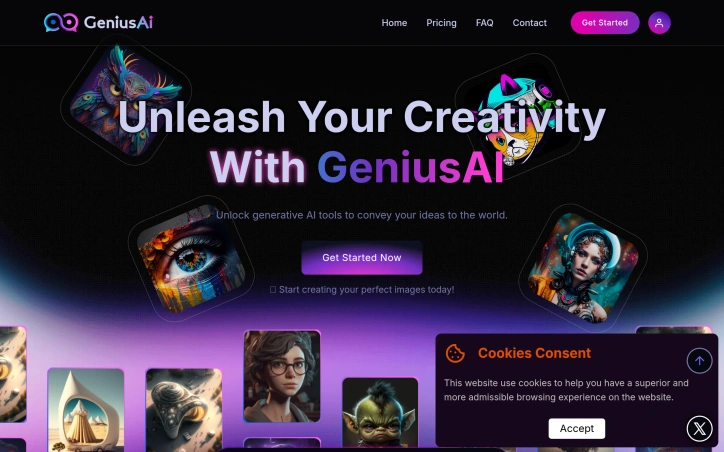

Graffiti Generator is built for creators, designers, students, content makers, small brands, street-art fans, and anyone who wants to turn words, names, tags, or prompts into graffiti-style visuals without learning complex design software. The platform combines free browser-based graffiti tools with AI-powered graffiti image generation. Users can create graffiti text designs, explore name and tag styles, browse graffiti letter pages, generate AI graffiti artwork from prompts, and download results for personal projects, social graphics, posters, stickers, moodboards, profile images, and creative concept work. Unlike a generic AI image generator, Graffiti Generator is focused specifically on graffiti and street-art workflows. It supports different creative entry points: a word, a name, a tag, a single letter, a full prompt, or a source image. This makes it useful whether someone needs a quick graffiti text preview or a more detailed AI-generated mural-style image. Graffiti Generator is designed for fast exploration and visual ideation. It helps users test graffiti styles, compare creative directions, generate readable lettering, and create urban-inspired visuals. The platform includes free tools, free starter credits for new users, and one-time paid credit packs for users who need more AI generations or higher-resolution output.
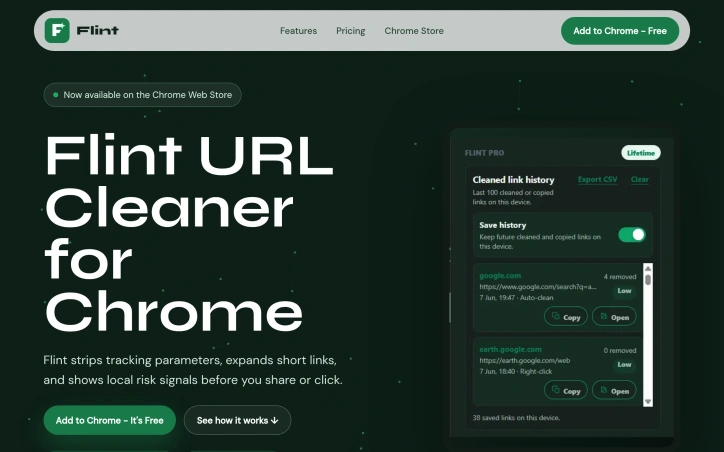
Tracking parameters embedded in URLs remain one of the most pervasive nuisances on the web, silently collecting behavioral data as links travel between users. Flint addresses this friction point directly with a Chrome extension that strips away UTM tags, Facebook click identifiers, and Google tracking codes while providing transparency into where links actually lead. The product targets everyday internet users who share links frequently and value privacy, but the clean-link premise extends beyond privacy advocates. Anyone who has puzzled over where a shortened URL actually points, or questioned whether clicking a link might lead somewhere unexpected, represents the core audience. What distinguishes Flint is its architecture: the extension performs its heaviest lifting locally within the browser, only contacting external services when users explicitly request certain features like short-link expansion or optional VirusTotal checks. This approach positions privacy as a structural choice rather than a marketing claim. The three-layer local risk model runs entirely client-side, surfacing qualitative signals about URLs without shipping sensitive browsing data anywhere. The feature set stays deliberately focused. Core functionality includes parameter stripping, hover previews that reveal destinations and flagged content, right-click menu integration for one-click link copying, and a paste-and-inspect mode for URLs users want to evaluate before visiting. Pro features add QR code generation, history tracking, custom rules, bulk cleaning, and the option to bring personal API keys for advanced threat checks from VirusTotal or Google Web Risk. The business model reflects this restraint. The core cleaner runs free indefinitely with no account requirement. The Pro tier costs fourteen dollars and ninety-nine cents as a one-time purchase, sidestepping the subscription model that dominates browser extensions and making upgrades genuinely optional rather than predatory. Flint succeeds by embracing scope discipline. It strips tracking parameters from links, reveals real destinations before users click, and does both while preserving browser performance. The local-first architecture and flat pricing model reveal a philosophy that treats users as stakeholders, not extraction targets.

Design exploration traditionally consumes time and money through multiple revision cycles. Whether adapting a kitchen palette, exploring exterior finishes, or conceptualizing landscape layouts, professionals and homeowners have historically chosen between expensive professional renderings or rough sketches that fail to communicate the full vision. ArchOne AI addresses this friction by offering a specialized visualization engine that converts reference photos into design variation studies across interior, exterior, and landscape domains. The platform targets interior designers, architects, landscape professionals, and design-conscious homeowners—anyone who needs to explore directional options before committing resources to execution. What distinguishes ArchOne from generic image-generation tools is its deliberate focus: it generates variations tied to specific design disciplines rather than attempting to be an all-in-one creative tool. Users can examine material palettes, lighting conditions, furniture arrangements, facade colors, planting schemes, and hardscape concepts all sourced from the same project image. The company is explicit about its boundaries. ArchOne is not CAD software, not BIM, not construction documentation, and not a replacement for structural or code review. This positioning is refreshingly honest—it occupies the ideation and communication layer, not the technical delivery layer. A designer can use it to show three different material directions to a client before investing time in detailed specifications or renderings. The feature set spans three integrated modules. The interior tool handles room concepts, layouts, materials, and ambiance. The exterior module focuses on facades, entry treatments, trim, and curb appeal. The landscape tool generates planting ideas, hardscape options, outdoor room concepts, and lighting. Each operates from the same input—a photo, sketch, or reference image—and produces client-ready visual options without requiring users to operate multiple platforms. The platform offers a free tier alongside paid options, lowering the barrier to trial. The gallery demonstrates realistic outputs across residential spaces: patios, kitchens, living rooms, garden concepts, and facade studies. Visually, these show competent AI image generation anchored to specific design constraints rather than unconstrained creative generation. For design professionals managing client communication cycles or homeowners testing ideas before hiring contractors, ArchOne compresses exploration phases that typically unfold over days or weeks of revision requests into minutes of iteration.

Streamlining visual content creation for non-designers has become a genuine market need, and Grok Imagine addresses it by combining text-to-video and image-to-video generation in a single interface. The tool targets creators, small production teams, and anyone who needs professional-grade visuals without mastering complex design software or waiting through long rendering times. The product's core value proposition centers on speed and accessibility. Generation happens in seconds rather than hours, with synchronized audio built into the workflow. The underlying xAI model produces what the company describes as cinematic results—expressive lighting, character consistency, realistic motion, and style fidelity. These aren't trivial accomplishments in generative media; competitors often struggle with temporal coherence in video or maintaining visual coherence across a sequence. Several features distinguish this offering in a crowded space. Commercial use rights come standard across all pricing tiers, removing a significant friction point for businesses that want to deploy generated content immediately. Privacy is positioned as a default; prompts and assets remain private and aren't shared with third parties, which appeals to creators handling sensitive or proprietary work. The generation history window scales with subscription level—90 days at the Pro tier, up to a full year for Max subscribers—giving users practical access to past work. The pricing structure uses a credit system rather than a pure subscription model, which allows flexibility. Monthly plans range from Plus at $9.90 to Max at $39.90, with credit allocations from 1,000 to 6,000 per month. One-time credit packs offer entry points for trial users or supplemental bursts. The per-credit cost improves with tier; Max subscribers pay $6.65 per thousand credits versus $9.96 for one-time purchases, incentivizing commitment. Pro tier—labeled as the popular option—sits at $19.90 with 2,500 monthly credits and priority processing, suggesting that's where the company expects mainstream adoption. What's notably absent from the marketing material are specific performance benchmarks, model architecture details, or comparative testing against competitors. The feature set is presented clearly but without quantitative validation. The pricing is transparent but unconventional enough that a potential customer would need hands-on experimentation to understand value per credit across different content types. For creators managing tight deadlines and those pricing out of enterprise tools, Grok Imagine delivers on its core promise: turning inspiration into finished visual content with minimal technical friction.

An AI-powered mobile application for personal beauty assessment and skincare planning, Beauty Score targets users who want instant feedback on their facial appearance and actionable steps toward improved skin health. The platform transforms selfies into multidimensional beauty insights, filling a gap between casual beauty curiosity and the friction of professional dermatology consultations. The core offering combines three interdependent functions. First, it generates a numerical beauty score from zero to one hundred, providing immediate quantifiable feedback. Second, it delivers face and skin analysis covering symmetry, emotional expression, age estimation, and specific skin conditions including blemishes, acne, and dark circles. Third, it constructs personalized skincare routines derived from the scan results. This layered approach moves beyond vanity metrics toward practical guidance. What distinguishes Beauty Score is its emphasis on usability and shareability. The analysis translates into step-by-step skincare recommendations rather than abstract commentary. Users can export findings as PDF reports or share aesthetic cards in six visual formats ranging from classic to Y2K styled, treating results as both personal tools and shareable social content. This dual positioning as entertainment and skincare reference broadens its appeal across demographics and use cases. The application leverages mobile convenience as a core differentiator. Available through both Google Play and the App Store, it requires only a smartphone camera and delivers results in seconds. The emphasis on speed and accessibility contrasts with traditional beauty consultations requiring time, cost, and geographic proximity to specialists. The product exercises appropriate restraint in its positioning. The published disclaimer clarifies that AI-generated recommendations constitute skincare inspiration rather than medical guidance, explicitly stating they should not replace professional care. This framing acknowledges the tool's entertainment value while establishing boundaries around health claims. Pricing information remains absent from publicly available materials, limiting assessment of the business model. The availability across both major mobile platforms suggests either freemium distribution or paid download, though specific monetization details require further investigation. Beauty Score targets beauty enthusiasts, skincare-curious consumers, and individuals seeking confidence through personalized appearance feedback. It functions simultaneously as a self-reflection tool, a skincare planning device, and social content generator. The product's core strength lies in packaging AI analysis into both accessible assessment and actionable routine, delivered at mobile scale.

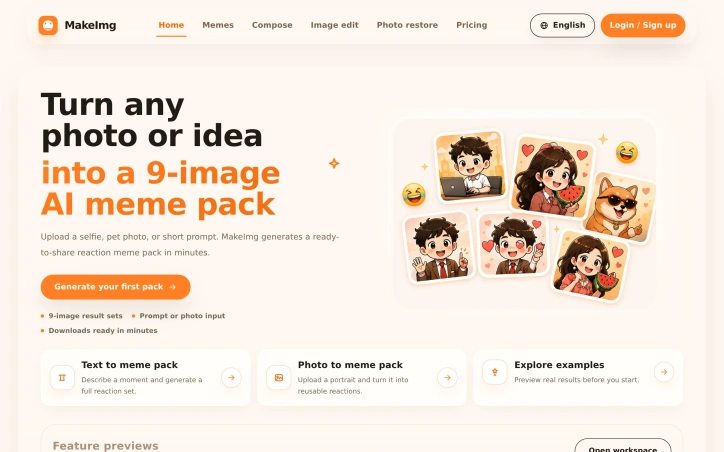
Transforming casual photos and idle ideas into polished visual content typically demands design skills, software expertise, and hours of editing time. MakeImg streamlines this process for creators who want fast turnaround on shareable meme packs without the friction. The core offering is straightforward: upload a portrait or describe a scene, and the platform generates a cohesive nine-image reaction set ready to download within minutes. This addresses a real gap for content creators, social media enthusiasts, and anyone who wants to produce on-brand visual assets without learning specialized tools. The service works across two main input modes—text prompts for conceptual meme packs and photo uploads for personal reaction sets—making it accessible regardless of whether a user starts with an idea or existing imagery. Beyond the headline meme-pack feature, the platform extends into adjacent creative workflows: image composition layers multiple reference photos into a single output, image editing lets users refine shots with text instructions, and photo restoration repairs old or damaged images. This breadth gives creators flexibility to complete different project types within one interface rather than toggling between specialized apps. The product philosophy appears centered on quick iteration and exploration. The platform includes a gallery of real generated outputs, positioning users to preview results before committing time, and emphasizes minute-level generation speeds. This matters for creators managing content calendars or capitalizing on trending moments. Pricing follows a familiar creator-tool playbook: a free starter tier for exploring the full workflow, a $9.99 monthly subscription pitched to regular generators, and a one-time $5 single-pack purchase for occasional users. The credit-based model allows scaling without forced subscription commitment, though the pricing page references credits without detailing exact generation costs per feature. What remains underexplored in the marketing materials is the consistency quality of output, particularly whether multi-image sets maintain visual cohesion across poses and expressions. Given the technical challenge of generating nine related images that function as true reaction options, this is worth validating before deciding if the tool fits professional creator workflows versus casual meme sharing. The positioning is solid for the target user: someone who values speed and ease over granular creative control. MakeImg occupies sensible territory between demand and execution, offering enough workflow options to feel like a complete toolkit while keeping the interface simple enough for non-technical users to generate results immediately.
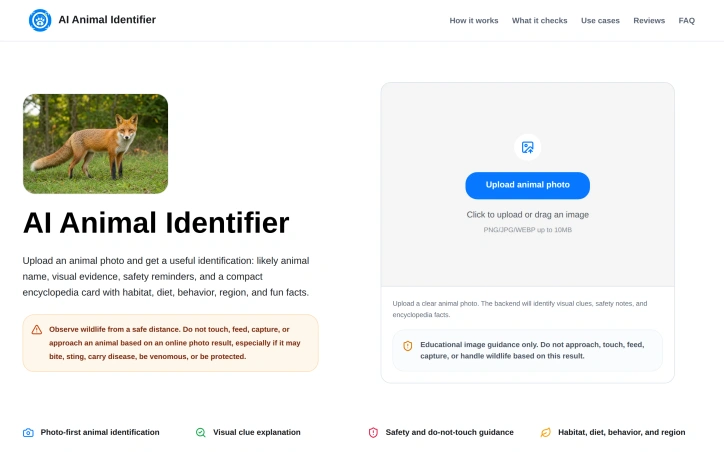
For anyone curious about an animal spotted in nature, a wildlife photo found online, or simply wondering about a creature in their yard, this browser-based identification tool fills a straightforward need. The product targets a broad audience spanning students researching wildlife, parents answering children's questions about animals, nature enthusiasts documenting sightings, and pet owners identifying unfamiliar creatures. The distinctive angle here centers on responsible wildlife interaction. Rather than simply naming animals, the platform pairs identification results with explicit safety guidance, reminding users not to approach, touch, feed, or capture animals based on photo recognition alone. This emphasis recurs throughout the interface and represents a thoughtful addition in an educational context where misidentification could lead to dangerous behavior. The core workflow is straightforward: upload an image in PNG, JPG, or WEBP format and receive the likely species identification along with supporting visual evidence. Beyond the name, users get habitat information, diet details, behavioral characteristics, regional context, and interesting facts. The platform indicates confidence levels in its guesses, an important transparency feature when stakes involve human safety around wildlife. The product addresses a common search behavior by organizing around specific user questions: "What animal is this," "Identify an animal by picture," and "What kind of animal is this." Rather than forcing all queries into a single form, these focused pages acknowledge how people actually ask these questions while maintaining the same upload-based identification mechanism. This mirrors how real search behavior works and makes the tool feel aligned with user intent rather than rigid. The decision to operate entirely in the browser eliminates friction present in traditional app-based identification tools, removing download requirements and installation steps. This approach democratizes access and positions the platform as a quick reference rather than a commitment download. The emphasis on visual explanation distinguishes this from simpler name-guessing alternatives. By showing what clues the model detected, the tool educates alongside identifying, useful for learning-focused users. The safety guidance strips away the novelty of AI identification and anchors the interaction to practical, responsible behavior. Pricing or monetization strategy receives no mention in available materials, leaving the business model unclear. The feature set and positioning suggest education and wildlife safety as core values, which shapes how the product positions itself even if commercial viability remains unstated.
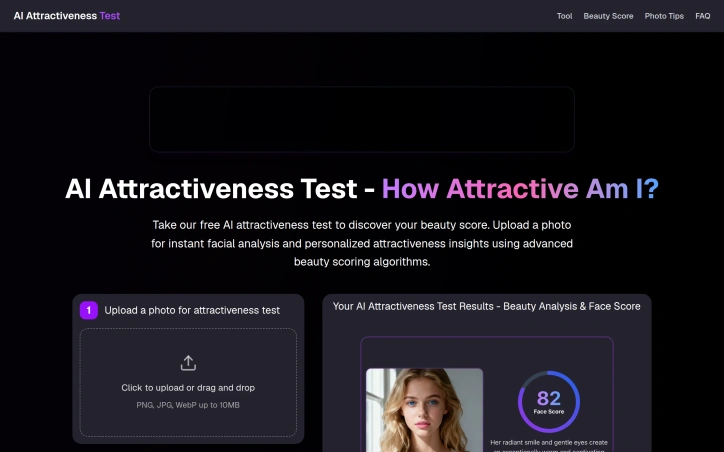
A browser-based tool that scores facial attractiveness using AI, this service appeals to the growing cohort of internet users curious about how machine learning perceives human features. The product serves dual purposes: it offers entertainment and quick visual feedback, while simultaneously demonstrating how AI models trained on large facial datasets respond to photographic variation. The core offering is straightforward. Users upload a photo, and the system analyzes multiple dimensions beyond raw attractiveness—including smartness, confidence, trustworthiness, fun, and approachability. Results arrive within seconds, accompanied by explanations of which facial attributes influenced the scoring. The interface requires no account creation or login, lowering friction for casual experimentation. What distinguishes this product is its transparency around its own limitations and variables. The site explicitly acknowledges that results fluctuate based on image quality, lighting, angle, and expression, positioning the tool as an educational instrument for understanding AI behavior rather than an authoritative beauty assessment. This framing mitigates some of the reputational risk inherent in any attractiveness-rating product. The accompanying guidance on photo selection—emphasizing clear, front-facing shots under good lighting—reinforces the educational angle and manages user expectations effectively. Privacy appears to be a selling point. The site claims photos are neither stored nor shared, addressing the obvious concern that facial data uploaded to a web service could be harvested or retained for model retraining. Whether this promise holds up to external audit is unclear, but it's presented prominently. The product leverages claims of sophisticated facial analysis trained on millions of images, examining symmetry, proportions, and skin quality. These claims align with capabilities available in commercial computer vision APIs but lack third-party validation or technical specificity on the site itself. From a business model perspective, the service is entirely free with no subscription tiers or upsells mentioned. Revenue generation remains unstated, leaving questions about sustainability and monetization strategy. Whether the business model relies on attention, data collection, affiliate arrangements, or another mechanism is not revealed. The product succeeds most clearly as a novelty tool that scratches an itch—what would an AI think?—while incidentally teaching users about how machine learning responds to visual input. It occupies an unusual position between entertainment and education, making it accessible to curious users without demanding serious engagement or personal investment.