Best Engineering & Development Startups & Tools
Recently Listed
72 launches
Privacy-conscious developers have few good options when it comes to AI-assisted coding tools. Most either bundle Chromium into their downloads, inflating file sizes to 150 MB or more, or require uploading projects to cloud servers. NativeCode addresses both issues by offering a compact, local-first alternative that keeps code on your machine while maintaining a minimal footprint. The product pairs a VS Code-inspired interface built on Monaco with your choice of local models running in Ollama, LM Studio, or any OpenAI-compatible server. The macOS download weighs just 7.11 MB because it leverages the system WebView built into modern operating systems — WKWebView on macOS, WebView2 on Windows — rather than shipping its own copy of Chromium. This design decision translates to meaningful storage savings without sacrificing functionality. Version 2.0 Beta, the latest release, significantly strengthens the core agent. It introduces plan mode for safe refactoring, project memory, reusable skills, pinned context, and self-review capabilities. The agent handles automatic context compaction and can access the web when needed. File and shell tool access is explicitly guarded, revealing a commitment to security over convenience. The tool supports every model its backend reports, with the ability to stream reasoning separately for models that provide it. Users can adjust thinking effort, switch backends or models without restarting conversations, and attach screenshots directly to vision-capable models. This flexibility removes friction when experimenting with different approaches or scaling up to more capable models. The business model is straightforward. NativeCode is free with no subscription requirement, no account creation, and no telemetry. The founder built this specifically because existing options either shipped unnecessary bloat or invaded privacy — frustrations many developers share. What emerges from these choices is a product designed around developer autonomy. It assumes users want control over their models, their data, and their tools, without paying for that privilege through subscriptions or data harvesting. For developers already running local LLM infrastructure or willing to set it up, NativeCode removes a major friction point: the need to choose between privacy, cost, and capability. Whether this approach catches on depends partly on whether developers embrace local inference as a default rather than a niche preference.

Developers building backend systems spend countless hours recreating the same database interfaces across projects: grids to list records, forms to add and edit entries, modals for data capture, export buttons. ArtiGrid targets this inefficiency by automatically generating complete CRUD interfaces from database table structures, converting what typically takes hours of manual coding into a configuration task. The tool addresses a real pain point for PHP developers working in Laravel, CodeIgniter, or vanilla PHP who need to expose database tables to internal teams or end users. Whether managing customer records, product catalogs, appointment schedules, or inventory systems, teams can configure ArtiGrid once and generate a working admin interface immediately rather than hand-building grids, forms, validation, and AJAX calls for every table. What distinguishes ArtiGrid from conventional CRUD generators is its framework-agnostic design. Rather than locking developers into a specific framework, it integrates into existing codebases without requiring architectural restructuring. The generated interfaces use an MVC-friendly approach, meaning teams can adopt it incrementally without rewriting their applications. The product goes beyond basic CRUD functionality. It includes AJAX-powered data grids that load without full page refreshes, built-in search and filtering, pagination, column sorting, and instant export to Excel, PDF, and CSV formats. More sophisticated use cases benefit from support for charts, dashboards, nested tables, and fields that understand database relationships. Automatic CRUD forms inside modals handle create and edit operations without requiring custom markup. For teams seeking an even faster workflow, ArtiGrid Builder Pro shifts the experience from code-based configuration to visual database browsing. Users point the tool at a table and receive a working admin panel ready for review and deployment, eliminating configuration code entirely. The tool supports PHP 8 and emphasizes fast load times through AJAX interactions that avoid full-page reloads. This focus on responsiveness applies even to generated admin panels that might traditionally feel sluggish. ArtiGrid solves a legitimate problem for PHP teams building administrative interfaces repetitively. Its framework flexibility and feature scope beyond simple CRUD make it a compelling option for back-office development workflows.

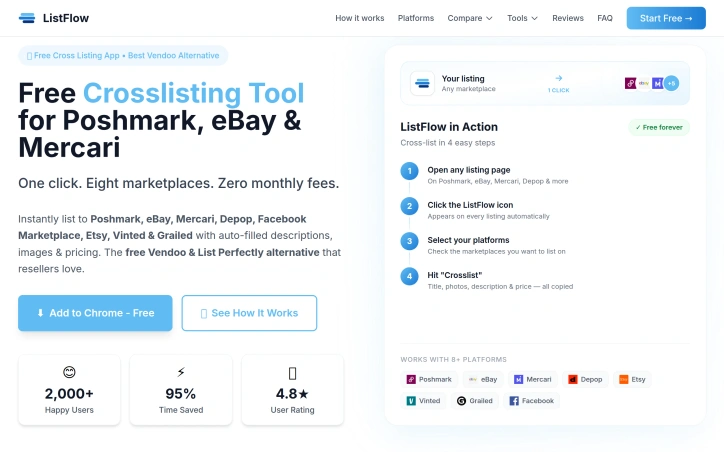
Resellers juggling multiple online marketplaces face a familiar pain point: manually recreating listings across Poshmark, eBay, Mercari, and beyond consumes hours each week, forcing many to pay premium subscription fees just to automate the process. ListFlow tackles this head-on with a stripped-down Chrome extension that eliminates both the busywork and the cost barrier. The product's core premise is straightforward. Users visit any listing on their source marketplace, click the ListFlow icon, select which platforms to cross-list to, and execute a single action. The extension handles the heavy lifting by copying product photos, descriptions, titles, and pricing across to eight supported marketplaces including Poshmark, eBay, Mercari, Depop, Etsy, Vinted, Grailed, and Facebook Marketplace. Setup takes approximately 60 seconds, and no credit card is required. What distinguishes ListFlow in a crowded field of crosslisting competitors is its commitment to the free model. Tools like Vendoo, List Perfectly, Crosslist, and PrimeLister charge between nine and ninety-nine dollars monthly, creating ongoing friction for price-conscious resellers. ListFlow removes that friction entirely by operating as a perpetually free service. This reflects a deliberate product philosophy: simplicity over feature bloat. The extension omits inventory dashboards and advanced seller tools that incumbents bundle in. Instead, it focuses narrowly on the core job: moving a listing from one marketplace to another instantly and reliably. User reception has been positive. The product carries a 4.8-star rating and reports over 2,000 active users. Published claims cite 95 percent time savings for crosslisting workflows, a natural consequence of the one-click mechanism. ListFlow handles image transfers automatically, preserving a critical element that lesser tools sometimes mishandle. Processing happens locally rather than on remote servers, adding a privacy angle that resonates with resellers concerned about their data. The positioning explicitly rejects the bundled dashboard approach common among competitors, betting that many resellers prefer focused tools over bloated platforms. The tool's limitation lies in its intentional narrowness. It solves the crosslisting problem and nothing else. Resellers seeking broader marketplace management, inventory tracking, bulk editing, analytics, or shipping integration must layer additional services on top. For sellers whose primary friction is repetitive listing creation across multiple platforms, ListFlow removes a genuine obstacle to scaling operations. For those with more complex operational needs, it functions as a capable but limited component of a larger toolkit rather than a comprehensive solution.

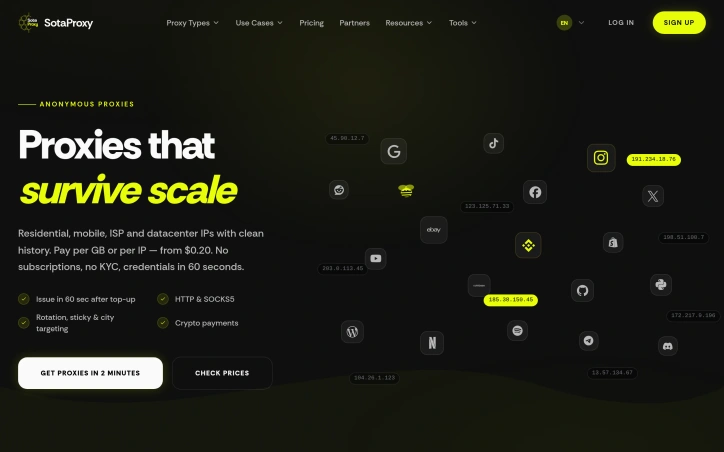
When it comes to managing proxies for automation and digital growth, reliability is paramount. SotaProxy addresses this need by offering an all-in-one proxy platform designed to simplify complex tasks. The target audience is primarily IT specialists and businesses that rely heavily on automation, web scraping, ad verification, and other digital tasks that require robust proxy management. What stands out about SotaProxy is its emphasis on reliability and trust. The platform boasts a 99.9% uptime, backed by a global network monitored 24/7, ensuring that automation tasks never stop. This focus on stability is underscored by its redundant server clusters and strict fair usage policy to maintain high trust scores for its IP pools. The platform is designed with the end-user in mind, providing secure payments and human support available around the clock. Key features of SotaProxy include a variety of proxy types such as residential, mobile, ISP, and datacenter IPs, each tailored to specific needs like web scraping, social media management, and market research. The platform offers flexible usage options, including rotation, sticky, and city targeting, with both HTTP and SOCKS5 protocols supported. Management is streamlined through a single interface, allowing users to switch locations and rotate IPs with ease. SotaProxy's business model is straightforward, with pay-per-use options starting at $0.20 per GB or per IP, and no subscriptions required. Cryptocurrency payments are accepted, adding to the flexibility. The process of getting started is quick, with account creation, top-up, and proxy allocation happening within minutes. Overall, SotaProxy is positioned as a reliable and flexible solution for businesses and IT specialists looking to manage their proxy needs efficiently.

Artists often struggle with the business side of their craft, from managing studio time to creating professional invoices. Nice Software addresses these needs with a suite of focused tools designed to simplify the workflow of working artists. At its core, Nice Software is built around the idea that studios don't need more software, but rather fewer small frictions that can hinder creativity and productivity. The company's founder, an artist themselves, has created a range of applications that cater to the everyday realities of being a working artist. One of the standout features of Nice Software is its suite of specialized tools, each designed to tackle a specific task. For example, Wax & Pigment allows artists to create custom oil paint recipes with precision and ease, while Painting Mirror provides a way to check perspective, value, and composition on a phone. Other tools, such as NotaTime Studio and NotaBill Studio, help artists track their time and create professional invoices. What's notable about Nice Software is its commitment to simplicity and accessibility. All tools are free to try, with no signup or credit card required. The pricing model varies across applications, with some offering a one-time purchase fee, while others have a free tier with optional paid upgrades. For instance, Wax & Pigment has a free tier and a paid tier starting at $4.99, while NotaTime Studio costs €12.99 as a one-time purchase. Overall, Nice Software is a valuable resource for working artists looking to streamline their workflow and focus on their craft. By providing a range of practical, easy-to-use tools, the company is helping to remove the small frictions that can hold artists back.

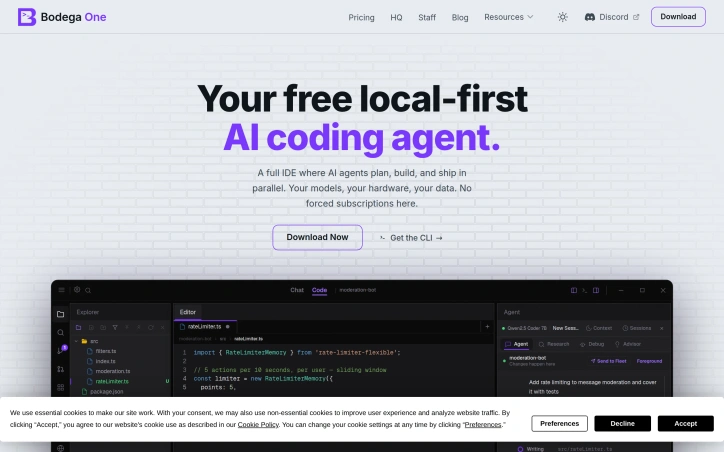
Developers who have grown weary of subscription-based AI coding assistants and the associated data privacy concerns now have an alternative. Bodega One Code addresses the issue of costly and proprietary coding tools by offering a local-first AI coding IDE that runs on the user's own hardware. What stands out about this product is its commitment to user ownership and control. By allowing users to choose their preferred large language model (LLM) and run it locally, Bodega One Code eliminates the need for reliance on third-party servers and the associated risks of data exposure. The product's air-gap mode ensures that sensitive information remains on the user's machine. The IDE itself is fully-featured, incorporating an AI chat and an autonomous agent that reviews its own work before completing tasks. Users can hand off tasks to the agent, which runs in the background on its own git worktree, allowing for parallel processing and isolated task management. The "Loops" feature enables users to automate recurring tasks, such as doc syncs and dead-code sweeps, on a scheduled basis. Notably, the product is available for download at no cost, with no forced subscriptions. Users have the flexibility to choose from over 10 LLM providers or run models locally using tools like Ollama or LM Studio. By decoupling the coding tool from subscription fees and proprietary infrastructure, Bodega One Code offers a compelling alternative for developers seeking a more autonomous and cost-effective solution. The product's design and features suggest that it is geared towards developers who value control over their coding environment and are looking for a customizable and extensible tool. By providing a local-first AI coding IDE, Bodega One Code is poised to appeal to developers who prioritize data privacy and are seeking a more flexible and cost-effective coding solution.

Engineering professionals in HVAC lose productivity shuffling between disconnected tools and reference materials to validate design decisions. This workspace addresses that friction by bundling calculators, technical data, and explanatory guides into a coherent system that moves engineers from problem to decision. The product centers on a practical workflow: engineers frame their inputs with known conditions, apply the appropriate calculator to the specific task, then validate assumptions through reference data and guides. This structure keeps decision-making grounded in context rather than isolated calculations. The toolkit spans three core HVAC domains. Duct design features sizing calculators for round and rectangular configurations, velocity checkers, friction loss analysis, and equivalent diameter comparisons. Load calculation tools aggregate cooling and heating components with documented inputs, alongside guides distinguishing design procedures from rule-of-thumb estimates. Refrigeration sections include capacity calculators and temperature-difference tools for evaluating system performance against measured state points. What distinguishes this workspace is the pairing of calculation tools with supporting reference material and decision guidance. Each tool sits within a broader context—guides explain methodology, references provide lookup data and formulas, and comparison sections help engineers choose between approaches. This architecture reflects a deliberate decision to treat context as foundational to sound engineering rather than optional validation. The update history suggests active maintenance, with multiple duct design and refrigeration tools updated within days of review. The workspace organizes itself around a clear taxonomy of paths: tools, reference material, decision comparisons, and explanatory guides. This structure should reduce time spent searching across disparate resources. The interface positions itself toward hands-on engineers rather than beginners. Terminology and tool complexity assume working knowledge of HVAC systems, pressure dynamics, and refrigeration cycles. Descriptions are direct and technical rather than introductory. No pricing model appears in available content. The workspace functions as a reference destination for professional use rather than a commercial product with listed costs. For HVAC design professionals managing multiple calculations daily, this hub addresses a real coordination problem: decision confidence depends on easy access to both the math and the reasoning behind it. By consolidating those elements, the tool eliminates the context-switching friction that fragments attention during design work.

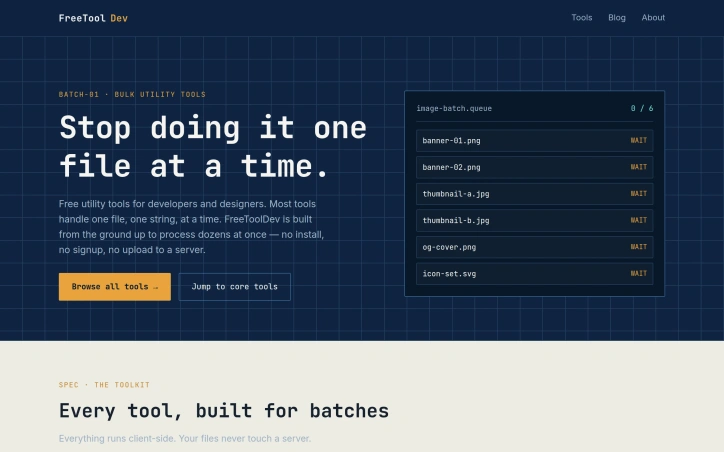
Developers spend countless hours processing files one at a time when bulk operations would save them significant time. FreeToolDev solves this problem by offering a free suite of utility tools built specifically for batch processing—everything from images to data formats to SEO metadata—all running directly in the browser. The product's core value proposition rests on three pillars: speed through parallel processing of dozens of files at once, privacy through client-side execution with no server uploads, and frictionless access requiring no installation, signup, or account creation. This combination addresses real friction points for developers who have either struggled with clunky command-line workflows or avoided online tools due to privacy concerns about uploading sensitive files. The feature set is impressively broad. Image tools handle batch resizing, conversion, and compression across PNG, JPG, and WebP formats. Data utilities cover CSV-to-JSON conversion, JSON-YAML bidirectional conversion, and JSON validation and formatting. For SEO professionals and developers, there's a site crawler that auto-generates sitemaps, RSS feeds, and llms.txt files while detecting broken links. Security-focused users get tools for bulk IP and DNS lookups, SSL expiry checks, and JWT decoding. The toolkit also includes niche utilities like QR code and barcode generators, bulk URL encoding and decoding, and meta title and description length checkers—the kinds of repetitive tasks developers typically cobble together from scattered tools. What distinguishes FreeToolDev from competitor tools is the genuine commitment to batch processing as a first-class feature rather than an afterthought. Most developer utilities handle one file or string at a time. FreeToolDev is architected around the assumption that users need to process multiple items in parallel. The browser-based architecture with client-side processing removes friction and addresses legitimate privacy concerns, ensuring files never leave the user's machine. The product positions itself squarely at developers and designers who regularly handle bulk file operations. The breadth of tools suggests the creator understood their own workflow bottlenecks and built solutions for each one. While the feature set is extensive, the unifying principle remains clear: take tedious, repetitive file processing and make it genuinely bulk-first. FreeToolDev operates on a pure free model with no indicated paid tier or monetization strategy. For developers seeking straightforward, privacy-first bulk utilities, the combination of breadth, accessibility, and zero cost makes this worth evaluating.

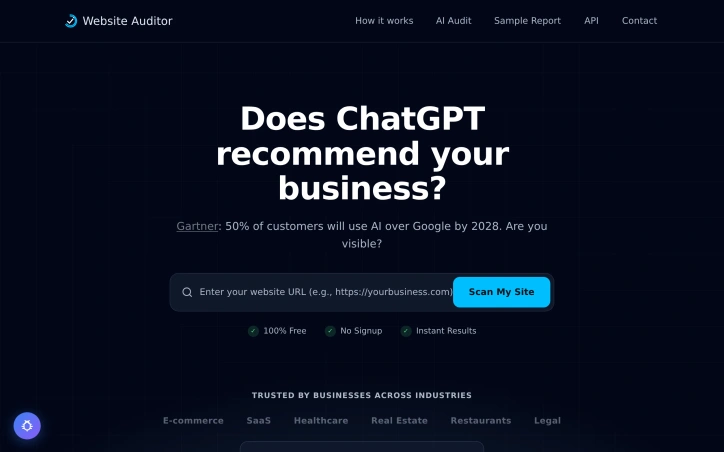
As artificial intelligence increasingly becomes the primary search method for consumers, most businesses remain invisible to these new tools. Website Auditor directly addresses this visibility gap by helping companies understand how they appear when customers use AI assistants like ChatGPT and Perplexity to research products and services. The problem the tool targets is substantive. Gartner's research predicts that half of customers will rely on AI tools rather than traditional search by 2028, creating a critical visibility challenge for businesses that haven't optimized for this shift. Website Auditor positions itself as the solution for small and medium businesses across industries, from e-commerce and SaaS to healthcare, real estate, restaurants, and legal services. What distinguishes the product is its focus on frictionless accessibility. The audit requires only two inputs—a business name and city—and delivers results in under a minute without requiring any signup or account creation. The tool scans how businesses appear in AI tools and local search results, simultaneously checking security and performance metrics. This stripped-down approach removes common barriers that prevent small business owners from adopting new tools. The execution reflects practical thinking about user friction. By eliminating login requirements and keeping the process instant, Website Auditor removes the excuses people cite for not trying new services. The interface is minimal enough that any business owner, regardless of technical sophistication, can run an audit in seconds. The product's reach across industries is notable. The company reports audits spanning 30 different sectors and over 200 websites. This breadth suggests the core problem transcends any single business type and reflects genuine cross-industry demand. Website Auditor operates on a freemium model. The basic audit is entirely free and anonymous, with no hidden paywalls. A paid tier at ten dollars monthly adds API access, allowing businesses to run up to five automated audits daily. This pricing structure makes sense for a discovery tool; it lets users validate the problem exists before committing budget. The tool's relevance will only increase as AI search becomes mainstream. By launching now and building brand awareness before this transition fully matures, Website Auditor positions itself as the obvious choice when businesses finally recognize their invisibility to AI.

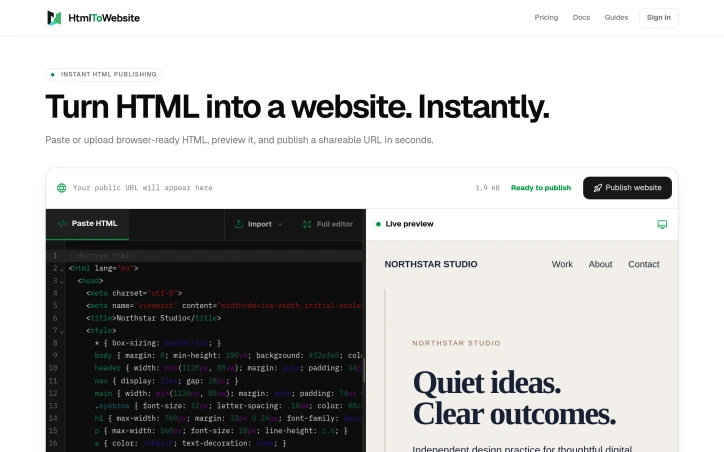
The friction point this solves is clear: developers who write HTML need a way to share their work publicly without wrestling with hosting infrastructure, deployment pipelines, or server management. HtmlToWebsite targets this gap by offering instant publication—paste your code and get a live URL, no deployment configuration required. The core value proposition centers on speed and simplicity. Rather than choosing between shared hosting platforms, containerization tools, or static site generators, users can move directly from editor to shareable link. This streamlines the typical workflow for prototyping, building demos, and iterating rapidly without backend complexity. The product handles projects of varying scope. Whether developers are publishing single HTML files or complex projects with accompanying assets, the platform manages the technical details transparently. This breadth is significant because many similar tools force users into either-or constraints—support for simple files OR full project structures, but rarely both seamlessly. Who benefits most? The platform appeals to developers building quick proof-of-concepts, designers prototyping interactive mockups, and educators demonstrating code concepts. It's also useful for teams collaborating on frontend-heavy features or anyone who needs to share executable code without asking collaborators to run a local environment. The strategic positioning is revealing. By eliminating hosting and deployment as friction points, HtmlToWebsite competes less with traditional web hosts and more with in-browser IDEs and pastebin services that now need distribution. It occupies the specific moment between code written and code running live, addressing a real bottleneck in development workflows. The product design is deliberately minimal—paste HTML, get a website—which works as both mechanic and marketing. There's no mention of pricing or business model in the available information, making it unclear how sustainable or commercially viable this approach is. Nonetheless, the core insight is sound: developers absolutely encounter this friction point, and removing it has genuine value for rapid iteration cycles and collaborative prototyping.
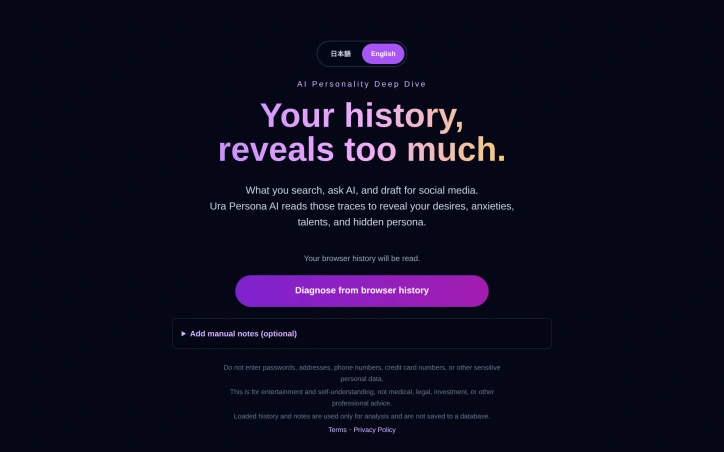
In an era when our digital traces accumulate silently—searches, draft posts, AI conversations—this application offers a different kind of self-reflection: analyzing your own data to understand patterns about desire, anxiety, and hidden interests. The product targets people curious about what their online behavior reveals about their deeper self, positioning itself squarely as entertainment and personal insight rather than any kind of professional guidance. The core offering is straightforward. Users provide their browser history and can optionally add AI chat logs, social media drafts, diary notes, or email excerpts. The application processes these inputs to generate a personality profile based on repeated patterns and behavioral signals. The technology identifies what matters to you through what you choose to search for, explore, and draft—treating your digital footprint as a window into unstated desires and anxieties. What distinguishes this product is its deliberate privacy stance. Rather than storing input data in a server database, the analysis happens client-side, with results cached only temporarily in the browser itself. This addresses a fundamental tension: people want insights into themselves, but hesitate to upload sensitive material to unknown servers. By keeping data local to the user's device, the tool removes that friction without requiring trust in cloud infrastructure. The application is bilingual, available in both English and Japanese. A clear disclaimer appears throughout the interface, specifying that outputs are for entertainment and self-understanding, not medical, legal, or investment advice. The tool explicitly forbids users from entering passwords, addresses, payment information, or other credentials, recognizing the risks of aggregating sensitive data. Result accuracy depends on input quality. The more concrete and specific the material provided, the sharper the analysis. Thin inputs produce thin outputs. This reflects honest positioning about algorithmic capabilities. The pricing structure remains unspecified in available materials. Whether the tool operates as free, freemium, or paid remains unclear. For now, Ura Persona AI occupies a narrow but distinct space: treating your own digital history as a source of self-knowledge, with privacy built into the architecture rather than as an afterthought.

Web development has long been dominated by WordPress and drag-and-drop platforms that promise quick solutions but deliver slow, bloated sites paired with ongoing monthly fees. BuiltToWinWeb addresses this pain point by offering hand-coded PHP websites built entirely from scratch with a single flat fee and no monthly subscriptions. The service caters to businesses across industries—law firms, accounting practices, construction companies, medical clinics, and digital agencies—that need professional websites to rank competitively on Google. Rather than choosing between expensive custom development and impersonal templates, clients get custom-built solutions designed specifically for their needs. What distinguishes BuiltToWinWeb from competitors is its commitment to code quality over convenience. Every website is built from raw HTML, CSS, JavaScript, and PHP without reliance on templates, plugins, or platform-specific constraints. This approach translates to measurable results: the company highlights a portfolio of over 100 custom sites with an average PageSpeed score of 98, faster load times than WordPress alternatives, and better search rankings. The founder credits lightning-fast performance as the reason sites built this way outrank platform-based competitors. The service offerings span business websites, ecommerce storefronts, custom database applications, and WordPress migration projects. Case studies demonstrate practical features tailored to industry verticals: law firms receive intake forms and case tracking, accounting firms get client portals and appointment booking, construction companies get project galleries with quote forms. These aren't added features bolted onto a generic template—they're designed into the site architecture. The business model reinforces the no-monthly-fees positioning. Clients pay a single flat fee upfront for a complete website and own the result entirely. Package options exist for different project scopes, with quotes provided within 24 hours. The tension worth noting: custom PHP development requires more upfront thought and potentially higher initial costs than WordPress solutions, and it trades the flexibility of plugin ecosystems for specialized development. But for businesses prioritizing performance, ownership, and search ranking—and willing to pay once rather than forever—the tradeoff reads as deliberate rather than limiting. BuiltToWinWeb occupies a specific niche: businesses that view their website as a long-term asset, not a platform to rent.

Creators constantly face friction when trying to save videos from social platforms—Instagram watermarks downloads, Facebook adds branding, and YouTube Shorts resists traditional saving. TezVid addresses this with a straightforward web tool that strips watermarks and captures original-quality footage across six major platforms in seconds. The service targets creators, marketers, and researchers who need to work with video content from Instagram, Facebook, YouTube, TikTok, Twitter, and Threads. The experience is frictionless: no extensions, no apps, no complex authentication. Copy a link, paste it, and the download arrives in your folder within 10 seconds. What distinguishes TezVid centers on speed and quality preservation. The platform maintains original HD resolution without re-encoding and processes most requests in under 10 seconds. A bulk-download feature for Pro subscribers handles up to 30 Instagram reels at once, appealing to agencies and archivists working at scale. Privacy stands out as a deliberate design choice. TezVid fetches videos in real time and never stores the actual files, only metadata for user history. This addresses legitimate concerns for creators handling copyrighted or sensitive content. The business model divides between a free tier offering 5 monthly downloads without payment information and a Pro plan starting at ₹299 per month in India, with regional pricing for Southeast Asia and Latin America. This structure targets growth markets where subscription adoption patterns differ from Western markets. The product's competitive moat is simplicity. While other video downloaders exist, the combination of multi-platform support, watermark removal, speed, and low entry friction creates clear value. TezVid reports more than 50,000 daily active users and carries a 4.9-star rating. For creators regularly working with video across multiple platforms, TezVid reduces the alternative: managing six separate tools or fighting platform limitations. The service fills that practical gap effectively.

Automating resource changes in Windows executables after compilation remains a tedious manual process for many development teams. Resource Tuner Console addresses this gap by providing a command-line interface that enables developers to modify resources in 32- and 64-bit Windows PE files without recompiling source code. The product targets Windows engineers, build managers, and DevOps leads who need to update application resources during the final stages of their build pipeline. It particularly suits mid-sized teams at companies between 20 and 500 employees that maintain dedicated release infrastructure, as well as smaller vendors and independent developers without dedicated release engineering staff. What distinguishes Resource Tuner Console is its focus on post-build workflow automation. Rather than treating resource editing as something that must happen at compile time, the tool enables teams to modify icons, version numbers, strings, manifests, and bitmaps as a scripted step after compilation completes. This separation of concerns offers concrete benefits: teams can adapt branding or patch versioning details without touching source code or recompiling, significantly reducing turnaround time for minor updates. The tool integrates into existing build automation by accepting command-line inputs and working within batch scripts or other Windows applications. The product emphasizes speed and consistency as primary value drivers. The marketing materials claim a substantial performance advantage over traditional GUI-based resource editors, positioning it as enabling teams to move faster and reduce human error when applying changes across multiple executables. For organizations that ship multiple versions of the same application or need to customize executables for different customers or partners, the ability to template these changes and apply them automatically addresses a real workflow pain point. Resource Tuner Console serves a specific use case within Windows development rather than attempting broad appeal. Its utility concentrates on scenarios where post-build resource customization offers enough friction reduction to justify the learning curve of command-line scripting. Teams already invested in build automation and release management processes will see the clearest value. Those still relying on manual resource editing or older GUI tools will find the switch worthwhile, though the tool assumes basic comfort with scripting and Windows executable formats.

Establishing an online presence begins with securing a domain name. For individuals, startups, and businesses, managing domain registrations, transfers, and renewals can be a tedious and overwhelming task. DomRegus simplifies this process by offering a comprehensive platform for domain management. The platform is designed to be intuitive and secure, providing users with a streamlined experience for registering and managing domains across over 150 extensions. Transparency is a key aspect of DomRegus, evident in its clear pricing structure. The cost of registering various domain extensions is explicitly stated, with prices ranging from $2.99 for a .xyz domain to $46.99 for a .ai domain. One of the standout features of DomRegus is its commitment to providing essential services alongside domain registration. Users are offered free DNS management and WHOIS privacy, empowering them to maintain full control over their domain portfolio. The platform also facilitates easy domain transfers and renewals, ensuring that users can manage their online identity efficiently. By combining trusted domain infrastructure with modern technology, DomRegus delivers a reliable and efficient registration experience. As an authorized OpenSRS reseller, the platform leverages established expertise to provide a secure environment for domain management. Overall, DomRegus is a robust solution for those seeking to secure and manage their online presence, offering a compelling blend of simplicity, transparency, and powerful management tools.
In today's digital landscape, productivity is often hindered by the need to install and manage multiple applications, each serving a specific purpose. CMDragon Tools addresses this issue by offering a comprehensive suite of online utilities that cater to diverse needs, from code formatting and image editing to file conversion and barcode scanning. The platform is designed for anyone seeking to streamline their workflow without the hassle of downloading and installing separate applications. What stands out about CMDragon Tools is its commitment to providing a seamless, browser-based experience that prioritizes user convenience and data privacy. The tools are carefully crafted to operate entirely within the user's browser, eliminating the need for server transmission and ensuring that sensitive data remains confidential. This approach is evident in tools like the EPUB Reader, which stores imported files locally and offers features such as customizable reading preferences, bookmarking, and full-text search. The platform boasts an impressive array of tools, including a Touch Screen Detection utility that performs comprehensive diagnostics and an advanced Barcode Scanner that supports a wide range of formats. These tools are not only feature-rich but also demonstrate a clear understanding of user needs, with functionalities such as live camera scanning, adjustable scan regions, and batch image decoding. By bringing essential utilities directly into the browser, CMDragon Tools simplifies workflows and enhances productivity. The absence of installation requirements, sign-ups, and server transmission aligns with the founder's vision of providing instant, no-download productivity. While pricing details are not explicitly mentioned, the platform's value proposition lies in its convenience, versatility, and commitment to user privacy, making it an attractive solution for individuals and professionals seeking to optimize their digital workflows.
For many organizations, SQL query writing remains a bottleneck. Non-technical team members struggle to access data independently, while developers waste time on complex joins and unfamiliar schemas. Existing AI-powered SQL generators typically demand a trade-off: convenience in exchange for uploading database schemas to third-party servers—a proposition that makes security-conscious teams uncomfortable. Text2SQL breaks this pattern by architecting the problem differently. Rather than accepting user data through its own servers, the tool operates entirely client-side. Users provide their own Anthropic API key, and queries flow directly from their browser to Anthropic's endpoints, bypassing Text2SQL's infrastructure entirely. This architectural choice eliminates a crucial security risk: the company never sees, stores, or logs database schemas, sample data, or query history. For organizations handling sensitive information or operating under compliance constraints, this design addresses a genuine pain point that most competitors ignore. The product itself centers on natural language translation. Users describe their data needs in plain English—"Show me customers who purchased last month"—and receive SQL queries in return. The tool accepts database schemas as CREATE TABLE statements and uses them to generate context-aware queries. An optional feature lets users upload example queries from their codebase; the AI learns naming conventions and join patterns, improving consistency across generated queries. What distinguishes Text2SQL is its completeness without overreach. It includes schema validation, query explanations, and sample data support with a thoughtful reminder that sensitive data should be randomized first. Session management allows users to save and restore configurations across visits. The tool enforces reasonable limits: 150 tables, 300 example queries, 3,000 sample data rows. These constraints prevent runaway complexity while accommodating realistic use cases. The product is entirely free. There's no licensing tier, no gating of core functionality, no hidden costs. This positions Text2SQL less as a revenue-generating product and more as a genuinely useful utility—potentially a customer acquisition strategy for Anthropic API adoption, or simply a commitment to reducing friction around database queries. For teams looking to democratize data access or streamline SQL development without surrendering control of their schemas, Text2SQL delivers on a clear promise. It won't replace domain expertise in complex analytics, but it meaningfully lowers the barrier to ad-hoc querying and frees developers from repetitive query construction.
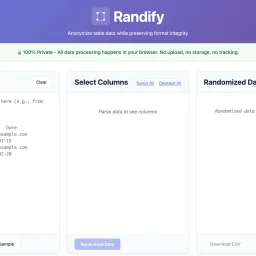
Privacy-conscious organizations managing sensitive data have long faced a troubling choice: anonymize customer or patient information for testing and demonstrations, or upload it to third-party services and accept the compliance and security risks. Randify eliminates that tension by processing all anonymization within the browser, never transmitting anything to external servers. The problem it targets is concrete. Development teams, QA engineers, and data analysts regularly need realistic test datasets without exposing actual customer records. Healthcare organizations must anonymize patient data for testing while maintaining HIPAA compliance. Financial services firms need to randomize customer information for development while staying PCI-compliant. SaaS companies want to demonstrate products with convincing but fabricated data. Randify addresses these scenarios through a single architectural commitment: all data stays local. What distinguishes the tool is its execution of this privacy-first model. It requires no registration and works offline, with zero network requests—users can verify this in their browser's developer console. For organizations subject to data protection regulations, this eliminates an entire class of security and compliance risk. The feature set reflects genuine practical needs. Rather than indiscriminately scrambling content, Randify lets users specify which columns to randomize and which to preserve, maintaining referential integrity so identical input values consistently produce identical outputs. The tool automatically detects PII patterns including email addresses, phone numbers, dates, names, addresses, and company names, applying appropriate formatting rules during randomization so results look realistic rather than obviously synthetic. It accepts data in multiple formats: CSV, TSV, pasted tables from spreadsheets, and SQL INSERT statements. Multi-language support for names and regional data patterns demonstrates attention to genuinely global use cases. The ability to preview changes before applying them reduces mistakes and friction. Randify is free and carries no monetization messaging in available materials, making it an accessible entry point for privacy-conscious teams. For organizations already skeptical of third-party data handling, a purpose-built, client-side-only solution occupies meaningful space in an otherwise server-dependent tooling landscape.

Organizations managing web infrastructure face a consistent blind spot: they discover outages through customer complaints rather than automated detection. A website might fail silently, an API might return errors intermittently, or performance might degrade without anyone noticing. UpTimeTools addresses this gap by providing continuous monitoring and alerting across websites, APIs, and servers, with instant notification when something breaks. The platform targets developers, IT operations teams, and digital agencies that need proactive visibility into service reliability. These users benefit from catching issues before customers encounter them, rather than learning about problems through support channels. Several product decisions distinguish UpTimeTools from conventional monitoring solutions. The platform combines basic uptime checking with synthetic testing—verifying critical user flows by running real browser tests that go beyond simple connectivity checks. API monitoring operates as a parallel capability, allowing independent tracking of back-end availability. Real user monitoring captures how services actually perform for visitors in production, revealing issues that lab conditions would miss. The alerting design confronts a real operational problem: false positives erode trust in monitoring systems. Group checks combine results from multiple sources to confirm genuine incidents rather than triggering on transient hiccups. Notifications fan out through SMS, email, phone calls, Slack, and other integrated channels, reducing the risk that critical alerts get missed. The feature set reflects operational maturity. Private location monitoring enables tracking of infrastructure behind firewalls. Custom status pages communicate incident status to stakeholders. Detailed reporting identifies performance trends and optimization opportunities. The platform operates 80 global monitoring points, enabling geo-distributed testing. The pricing structure emphasizes accessibility. UpTimeTools operates on recurring subscription plans with no credit card required to begin using the service. The company bundles synthetic monitoring, API monitoring, and 20+ integrations into all plans rather than reserving them for premium tiers, positioning comprehensive monitoring as baseline functionality. Premium plans include unlimited user accounts, enabling growing teams to scale without per-user surcharges. Single sign-on works across all subscription levels. The platform delivers enterprise-class capabilities—synthetic testing, real user monitoring, alert routing, incident status pages—with emphasis on simplicity. For teams that can't justify dedicated monitoring engineers or afford enterprise monitoring platforms, UpTimeTools provides a practical alternative that starts simple and grows with operational complexity.

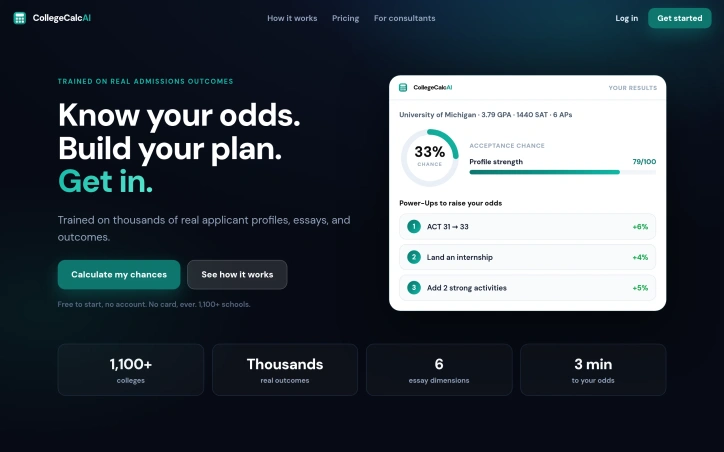
Navigating the complex college admissions landscape can be daunting for students, with numerous factors influencing their chances of acceptance. CollegeCalcAI directly addresses this challenge by providing a data-driven platform that empowers students to understand their odds of getting into specific colleges and universities. The platform is designed for high school students seeking to make informed decisions about their college applications. What stands out about CollegeCalcAI is its use of real admissions outcomes to train its AI models, allowing it to provide personalized and accurate estimates of a student's chances of acceptance. The platform considers a wide range of factors, including academics, test scores, extracurricular activities, awards, and essays, to give students a comprehensive understanding of their profile strength. The platform's key features include a free acceptance calculator that provides instant odds for over 1,100 colleges, along with a profile score and suggested "Power-Ups" to improve their chances. For a deeper analysis, the Advanced AI feature offers school-specific insights, highlighting a student's strengths, gaps, and next moves. Additionally, the platform provides essay review services, scoring essays against the target school's expectations. CollegeCalcAI operates on a freemium model, with the basic acceptance calculator available for free and no account required. Upgrades are available for students seeking more in-depth analysis, with the Advanced AI feature priced at $9.99 per month. The essay review service is available for $19.99 per month or $89.99 per year, with a 7-day free trial offered. Overall, CollegeCalcAI provides a valuable resource for students navigating the college admissions process, offering data-driven insights to inform their application strategies.